





编辑丨&
预测蛋白质功能的计算方法对于理解生物学机制和治疗复杂疾病具有重要意义。然而,现有的预测计算方法缺乏可解释性,难以理解蛋白质结构和功能之间的关系。
在研究中,来自中南大学的团队提出了一种基于深度学习的解决方案,名为 DPFunc,用于使用域引导的结构信息进行准确的蛋白质功能预测。
DPFunc 可以在结构域信息的指导下检测蛋白质结构中的重要区域并准确预测相应的功能。它优于当前最先进的方法,并与现有的基于结构的方法相比取得了显著改进。
他们的研究成果以「DPFunc: accurately predicting protein function via deep learning with domain-guided structure information」为题,于 2025 年 1 月 2 日刊登在《Nature Communications》。

详细分析表明,结构域信息的引导有助于 DPFunc 进行蛋白质功能预测,能够检测蛋白质结构中与其功能密切相关的关键残基或区域。故而,该方法是大规模蛋白质功能预测的有效工具。
DPFunc 概述
DPFunc 是一种基于深度学习的方法,用于使用域引导结构信息进行蛋白质功能预测。
它由三个模块组成:基于预先训练的蛋白质语言模型和图神经网络的残基级特征学习模块;蛋白质水平特征学习模块;蛋白质功能预测模块。
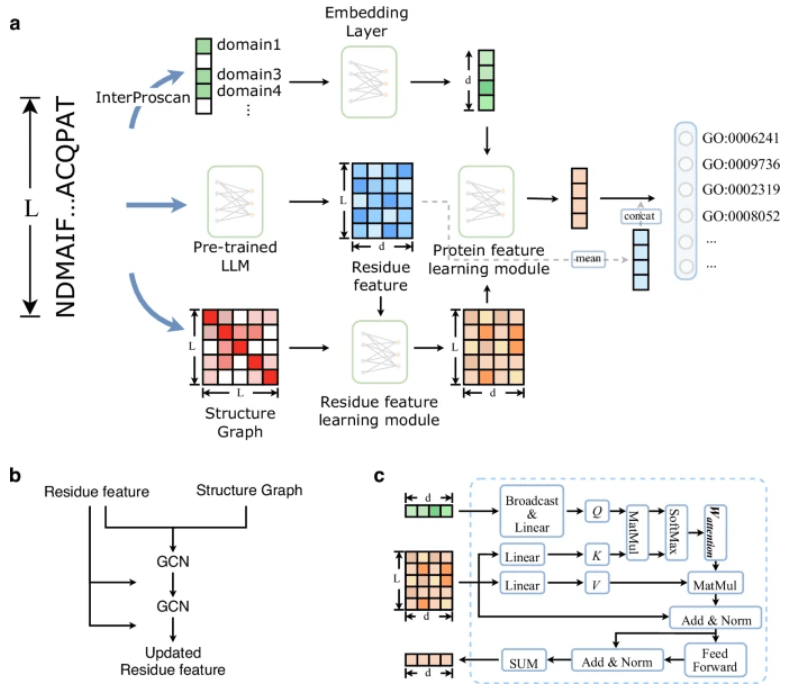
图 1:DPFunc 的模型架构。(图源:论文)
残基水平特征学习模块将蛋白质序列和结构作为输入。它首先从预训练的蛋白质语言模型(ESM-1b)中为每个残基生成初始特征,根据相应的蛋白质结构构建接触图。随后,这些接触图和残基层特征被进一步馈送到几个图神经网络(GCN)层中,以更新和学习最终的残基层特征。
为了评估不同残基的重要性,受 transformer 结构的启发,团队引入了一种注意力机制,将蛋白质水平的结构域特征和残基水平特征交织在一起,从而检测每个残基的重要性。
预测结果通过通用的后处理程序进行处理,以确保与基因本体论(GO)项结构的一致性。
为了获得模型的性能,团队将其与与仅基于序列和两种基于结构的方法进行公平比较。他们采用了以前使用过的数据集,在其他模型平均得分近似的情况下,新模型的性能超过了现有模型一大截。这一发现表明,蛋白质序列中包含的结构域信息为蛋白质功能预测提供了有价值的见解。
模型性能分析
团队根据不同的时间戳将大规模数据集划分为训练集、验证集和测试集。与以前使用的 PDB 数据集不同,这个大规模数据集包含更多的蛋白质和相应的附加信息。
为了确保公平的比较,标准化的方式被应用于后续的所有处理过程。
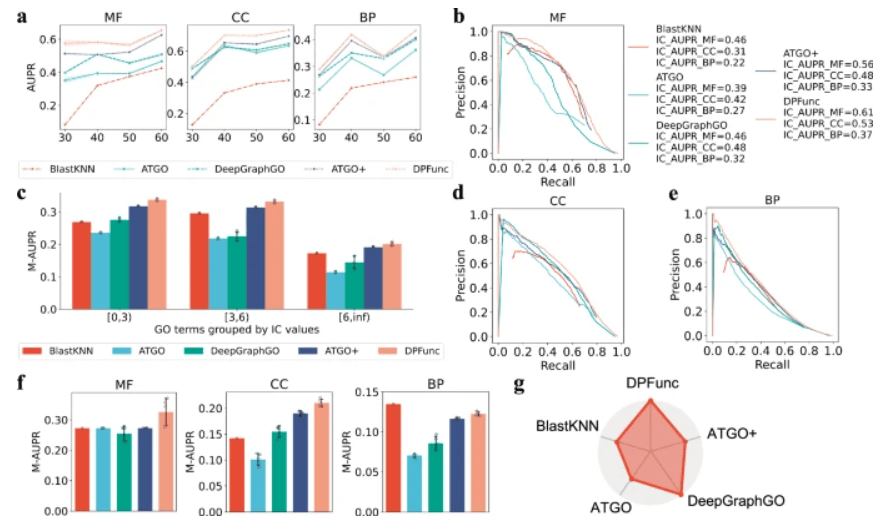
图 2:模型性能的详细分析(图源:论文)
除了整体性能之外,DPFunc 还擅长预测具有高 IC 值特征的信息性 GO 项。由于这些项出现次数少且训练样本有限,因此带来了更大的挑战。在预测样本较少的 GO 项时,DPFunc 的性能始终优于其他方法。
DPFunc 表现出优于 SOTA 方法的明显优势,特别是它能够处理具有低序列同一性的不可见蛋白质、具有高 IC 值的信息性 GO 项以及具有更深节点的特定 GO 项。
为了明确证明域信息在 DPFunc 中的关键作用,团队采用平均池化层替换了域注意力块。凭借领域洞察力,DPFunc 的几个模块中的 AUPR 中位数分别提高了 12.0%、14.7% 和 16.3%。这些结果明确证实了整合结构域信息进行蛋白质功能预测的无与伦比的价值。
为了进一步说明 DPFunc 在检测相似结构基序方面的潜力,即使没有序列相似性,团队也进行了两个案例研究。对两种将细胞与外部环境分离的关键质膜蛋白,DPFunc 能够捕捉结构相似性并准确预测功能,即使面对不同的序列也是如此,突显了它在蛋白质功能预测方面的巨大潜力。
除此之外,DPFunc 可有效检测酶功能的重要活性位点。这种非凡的能力归功于图神经网络的强大功能,它可以聚合来自两个相邻活动站点的信息。不过,尽管 DPFunc 有效地进行了检测,但在无序区域寻找活性位点仍然是一个挑战,可能会在未来的模型中进一步探索。
学习模块
团队使用两个数据集来评估其方法的性能。前者是一个非冗余集,通过以 95% 的序列同一性对所有 PDB 链进行聚类。后者是从 UniProt 和 Gene Ontology 数据库中收集的。
DPFunc 整合了这两个模块并预测了蛋白质功能。具体来说,它利用初始残基特征和蛋白质特征来注释功能。此外,一旦该模型经过训练,它就可以根据注意力机制检测结构中的重要残留物。
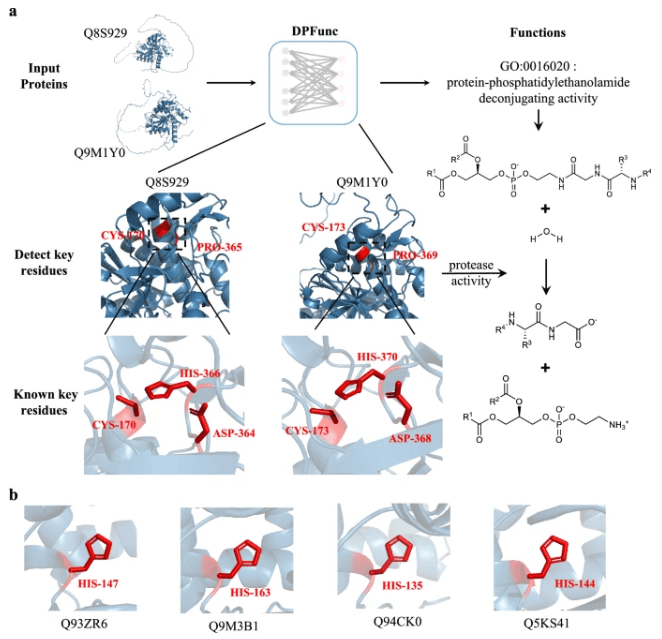
图 3:DPFunc 检测到的关键残基。(图源:论文)
小结
结合了结构域引导的结构信息来识别蛋白质结构中的关键区域,从而能够根据潜在结构基序和关键残基准确预测功能。与其他最先进的深度学习方法的全面比较证明了此次提出的方法的优势。
DPFunc 在稀有功能、特定功能和与已知蛋白质序列相似性较低的困难蛋白质方面也优于其他方法。其表现出区分不同结构之间蛋白质的令人印象深刻的能力。DPFunc 可以学习相似的结构基序,即使它们的序列相似性并不如训练集那么高。
DPFunc 仅使用蛋白质序列作为起始量。具体来说,它通过扫描序列生成结构域信息,通过预先训练的蛋白质语言模型提取残基特征,并根据预测的结构构建结构图。
由于蛋白质在细胞环境中执行功能,因此它们的功能会随着环境而动态改变。如何准确预测动态函数是未来需要解决的另一个挑战。
原文链接:https://www.nature.com/articles/s41467-024-54816-8



