




近日KDD CUP 2023和RecSys Challenge 2023数据竞赛相继落下帷幕。来自全球60+国家,2000+参与者经过数月的激烈角逐,认知智能全国重点实验室组成的团队基于自研的推荐系统算法库,RecStudio,在多项赛道中取得佳绩。其中,在KDD CUP 2023中,ustc-gobble团队获得“下一个标题生成”赛道第二名,unirec团队获得“下一个产品推荐”赛道第三名(两个赛道第一名都是拥有全职工程师和强大算力的英伟达团队),而在RecSys Challenge 2023,TOT团队获得Academia赛道第三名。
数据科学竞赛通常要求参与者针对某一特定问题或数据集开发高效的模型,这涉及到频繁地尝试各种先进的模型,并构建合适的数据处理、模型训练和测试的框架。由于这些挑战,参与者往往需要投入大量的时间和精力在模型的实现和框架搭建上,推荐系统领域也不例外。为此,认知智能全国重点实验室团队依靠其自主研发的推荐算法库RecStudio在多个推荐系统赛道中取得佳绩。在比赛过程中,团队也深刻体会到RecStudio显示的优势:
RecStudio提供了统一的数据结构和配置文件对数据进行处理。比赛中提供的数据经过简单的处理,即可被RecStudio接受。 RecStudio提供了高效的训练和测试框架,支持常见的测试指标,可以避免繁琐的搭建框架的过程。 RecStudio中实现的推荐模型包括召回模型和精排模型两类,可以支持常见的大规模数据召回任务和CTR预估任务。 RecStudio实现了90个已有的推荐模型,用户可以基于这些模型快速集成,提高性能。 RecStudio支持模块化的模型设计,用户可以快速地定制自己的模型。 RecStudio支持自动化调参,用户配置完调参设置,即可快速对模型调参,提升模型性能。
本文将介绍RecStudio推荐算法库以及该团队在多个竞赛中的解决方案。
RecStudio

论文:Defu Lian, Xu Huang, Xiaolong Chen, et al. RecStudio: Towards a Highly-Modularized Recommender System[C]//Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2023: 2890-2900. 仓库链接:https://github.com/ustcml/RecStudio.
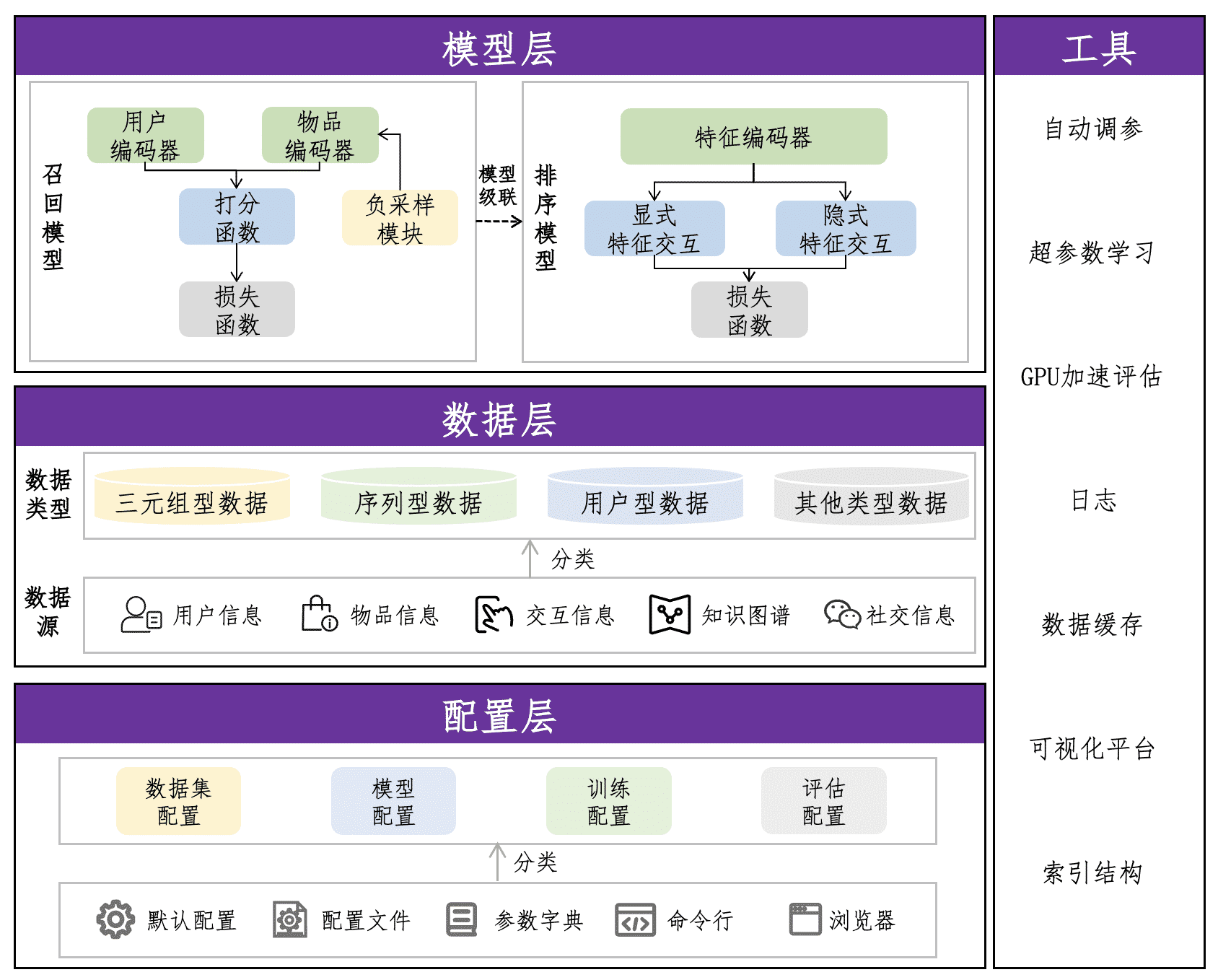 RecStudio框架图
RecStudio框架图RecStudio是一个基于pytorch的统一的、高效的、模块化的推荐系统算法库,其中实现了90个推荐系统模型。RecStudio的模块化模型设计让用户能够以简便的方式对模型中的某一模块进行替换、改进,并且可以快速地定制新模型,这使得RecStudio在真实推荐系统应用场景中更具实用性。具体来说,RecStudio有以下主要特点:
模块化的模型设计:RecStudio将推荐系统模型分解为若干模块,包括用户/物品编码器、采样器和损失函数等,用户可以如同搭积木一般快速定制自己的模型。 统一的数据集结构:通过统一的配置文件和数据结构,RecStudio简化了数据集处理流程,为各种类型的推荐系统模型提供了坚实的数据支持。 高效的训练和推理:RecStudio确保了训练、推理以及评估过程均能充分利用GPU进行加速。 良好的使用体验:RecStudio不仅提供命令行和浏览器等多种运行接口,还通过配置文件、参数字典等多样化的配置接口,实现了自动调参、自动下载数据集和数据集缓存等功能,全方位地提升了用户的使用体验。
KDD CUP 2023 “下一个产品推荐”挑战赛
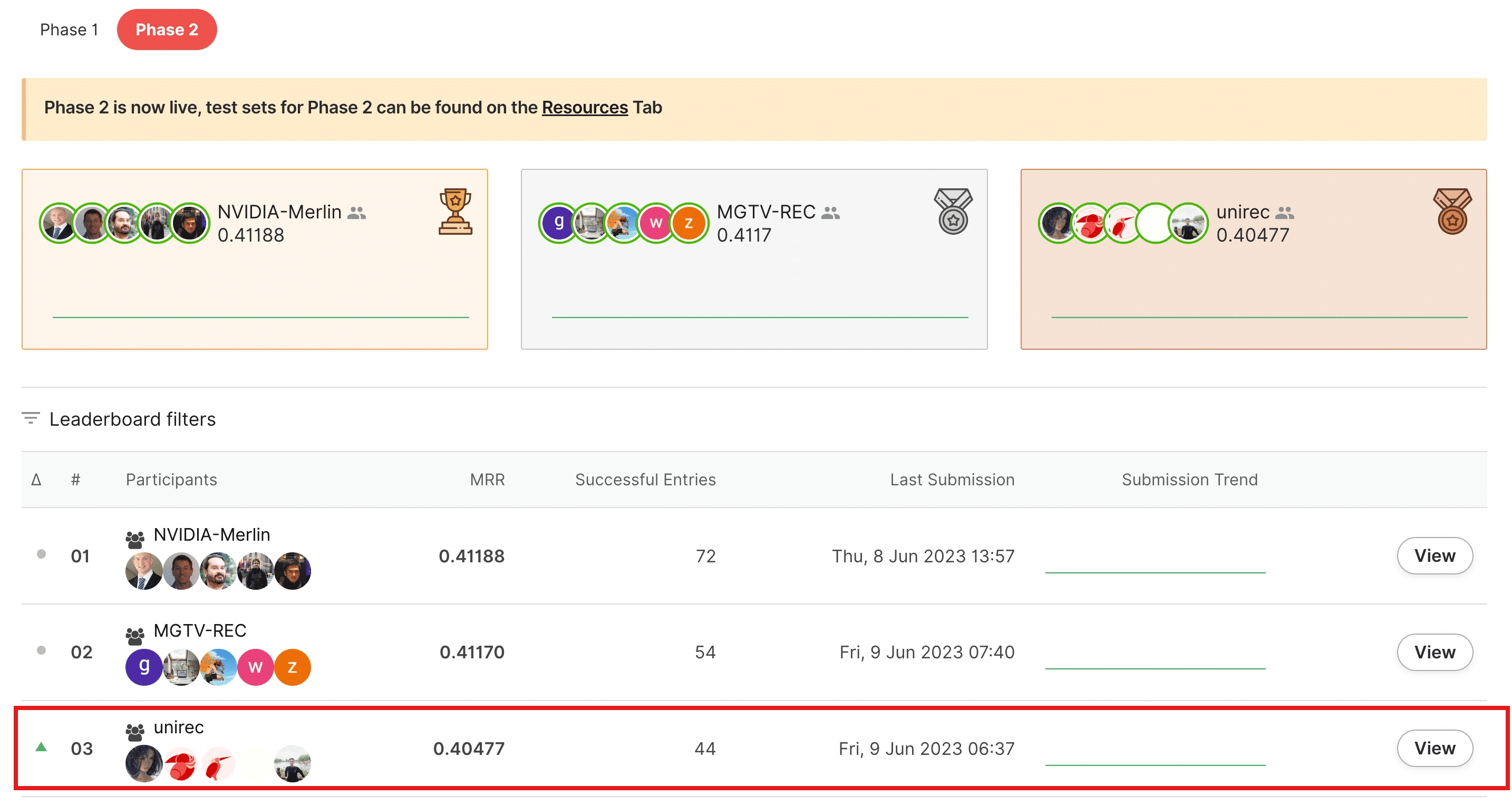 竞赛结果
竞赛结果
团队成员:雷雨轩、陈晓龙、张沛炎、连德富、练建勋、李朝卓 方案论文:Yuxuan Lei, Xiaolong Chen, Defu Lian, et al. Practical Content-aware Session-based Recommendation: Deep Retrieve then Shallow Rank[C]//Amazon KDD Cup 2023 Workshop. 2023. 开源链接:https://github.com/Xiuchen519/Amazon-KDDCUP-23
比赛介绍
KDD CUP(国际知识发现和数据挖掘竞赛)是由美国计算机协会知识发现与数据挖掘专委会(ACM SIGKDD)发起的国际公认数据挖掘领域最高水平、最具影响力、规模最大的国际顶级竞赛,被誉为“数据挖掘领域的世界杯”。今年,KDD CUP与亚马逊联合举办的"下一个产品推荐"挑战赛,旨在根据客户的会话数据和每个产品的属性来预测客户下一个可能访问的产品。与传统基于会话推荐的任务不同,在本次任务里,不仅需要利用好用户物品间基于ID的协同信号,同时还需要有效利用提供的产品属性(标题、描述、价格、品牌等等)来增强推荐效果。在本次任务中,主办方提供了一个"多语言购物会话数据集",需要对数据量较为丰富的英语、德语、日语三个地区进行产品推荐。
技术方案
核心思路是采用经典的召回-排序两阶段策略。在召回阶段,使用三种类别的单模型(会话推荐模型,文本模型,基于统计的模型),来从全量物品集里召回少量候选集,同时获取会话到物品的得分特征;在排序阶段,采用XGBoost,基于各种得分特征以及人工设计特征来对候选集进行排序,得到最终推荐结果。
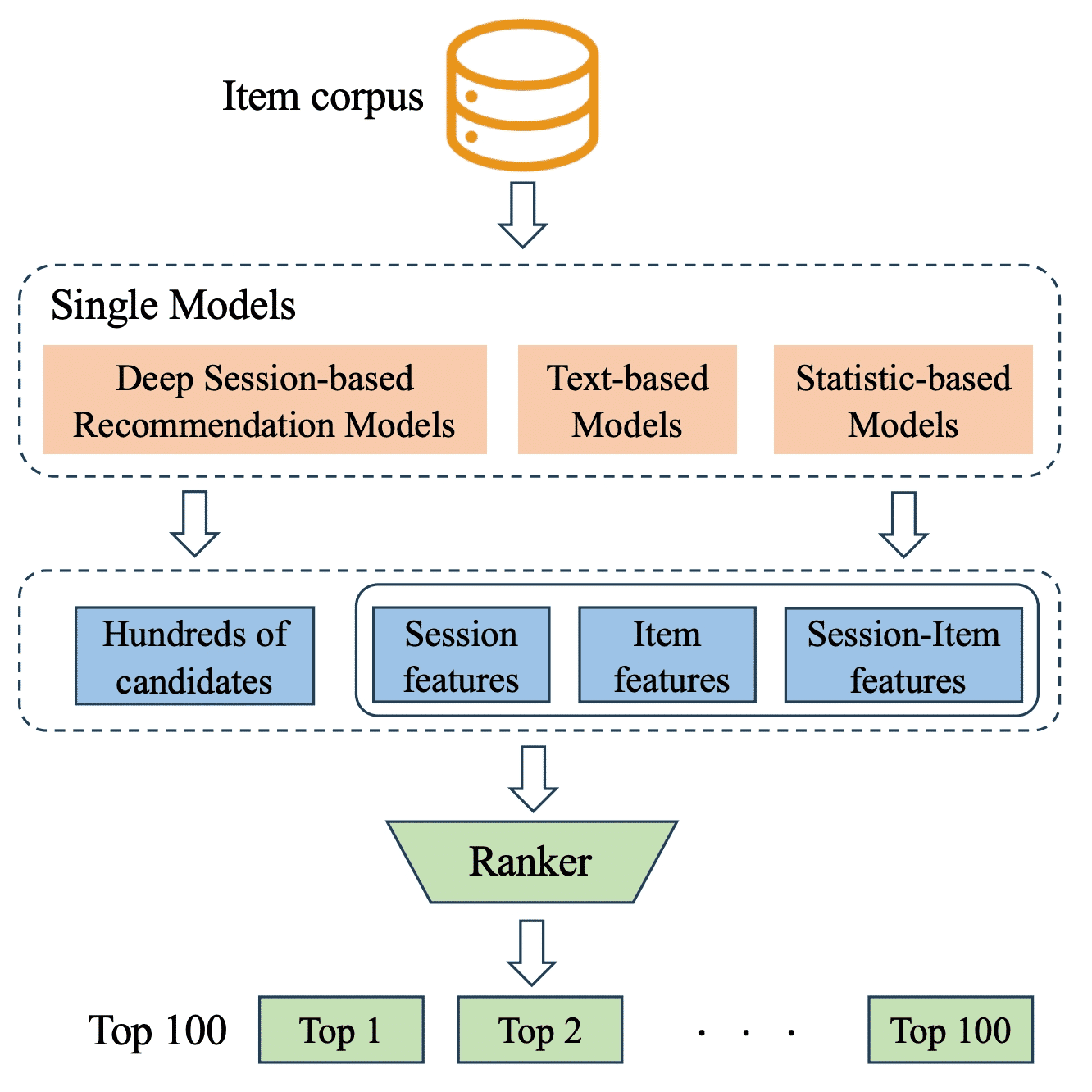 模型框架图
模型框架图
召回阶段
深度会话推荐模型:首先,使用了多种不同网络架构的会话推荐模型(SASRec[1]、GRU4Rec[2]、NARM[3]等),并在基于ID的会话推荐算法基础上,额外引入了三个通用的增强会话推荐的方法。
特征增强:将产品的类别和数值特征编码为嵌入,将其与ID嵌入加在一起一起训练。 文本增强:基于产品的标题、描述,利用语言模型训练得到了产品的文本嵌入,并将其固定住,用可学习的MLP层转化到ID嵌入的向量空间,再加和在一起用来表征物品。 持续学习:在正常训练阶段,把每个会话历史拆分成多份来增加训练数据量,但这会导致训练时会话长度与测试集的会话长度存在很大不一致性。所以在正常训练完后,会加载训练好的模型参数,再只基于训练集里每个会话的最后一个物品标签来进行训练。
文本模型:利用BERT系列模型来基于产品的标题、描述等文本信息训练得到产品的文本表征,这有助于:(1)增强会话推荐模型效果,(2)文本模型本身也可以作为基于内容的会话推荐模型使用,生成丰富的得分特征用于排序阶段。这里有两种实现方式:
User2item:用两个编码器分别编码会话和目标产品的表征,其中会话文本是将会话内所有产品的文本拼接得到。 Item2item:用一个编码器编码产品表征,并基于会话数据构建正产品对来用于训练。
基于统计的模型:使用了传统的ItemCF[4]、UserCF、共现图方法来获取候选集和统计分数特征。
排序阶段
首先用SASRec、xlm-RoBERTa、共现图模型分别召回前150个候选物品并将三者结果合并作为排序阶段的最终候选集。然后基于单模型阶段获取的会话到物品的分数特征以及会话特征、产品特征来训练XGBoost做为最后的排序模型。值得一提的是,团队发现在产品特征里,下一个产品频率非常有用,而对于分数特征,对其进行softmax或者min-max正则化也十分有效。
KDD CUP 2023 “下一个标题生成”挑战赛
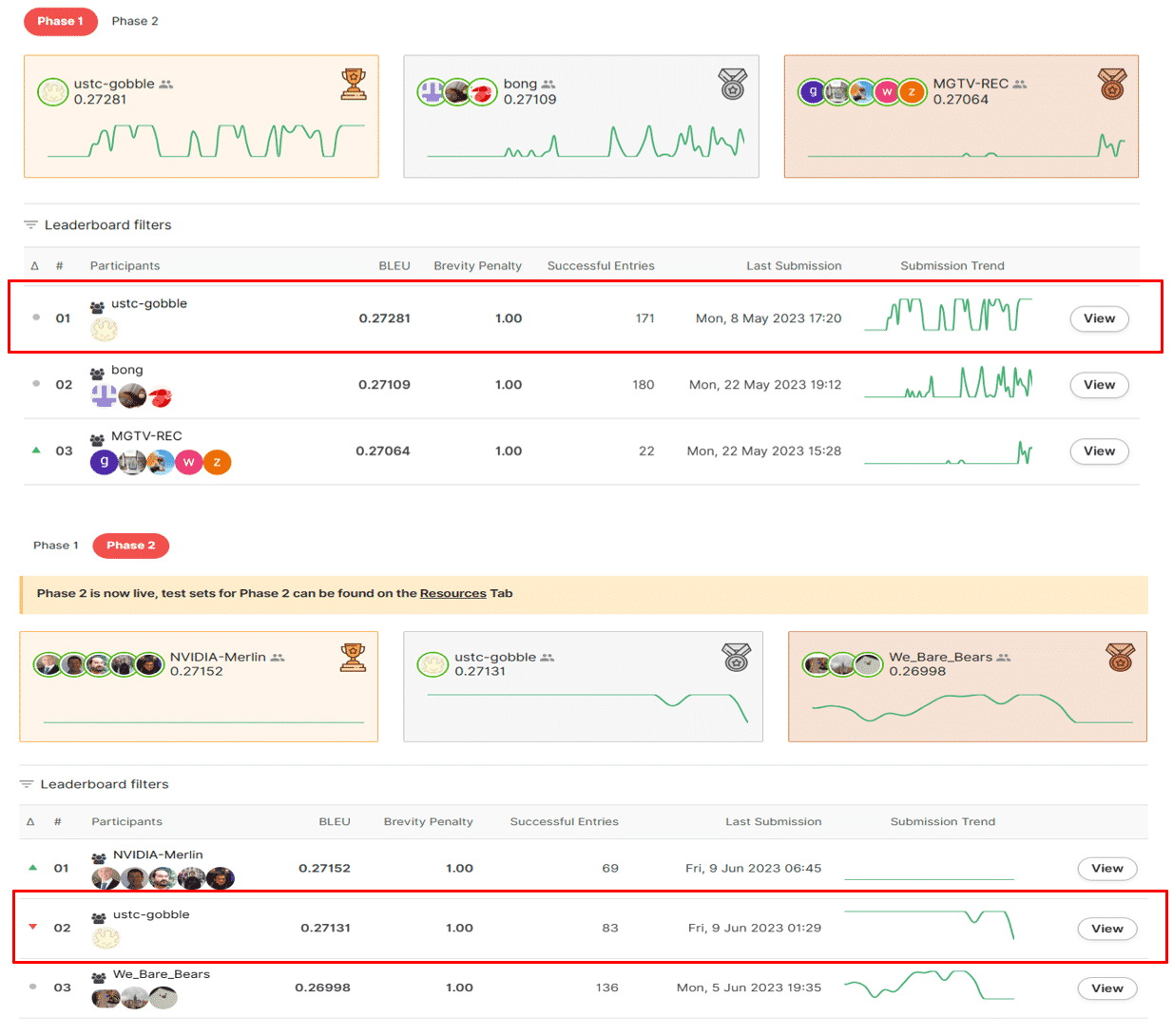 竞赛结果
竞赛结果
团队成员:吴陈旺、邓乐言、朱志豪、连德富 方案论文:Chenwang Wu, Leyan Deng, Zhihao Zhu, Defu Lian. Co-visitation Meets Token Alignment for Next Product Title Generation[C]//Amazon KDD Cup 2023 Workshop. 2023. 开源链接:https://github.com/Daftstone/kdd-cup-task3
比赛介绍
KDD CUP与亚马逊联合举办的另一个赛道:“下一个标题生成”挑战赛,旨在根据客户的会话数据预测客户将与之互动的下一个产品的标题。与传统专注于推荐现有产品的任务不同,预测新产品或“冷启动”产品是一项独特的挑战。生成的标题有可能改进各种下游任务,包括冷启动推荐和navigation。对于该任务,主办方使用了bilingual evaluation understudy (BLEU)作为评估指标,其通过将生成的候选项与一个或多个参考项进行比较来评估自然语言生成的质量。尽管BLEU能够客观地评价标题的一致性,但它也存在局限性,如无法捕获人类的主观感受。例如,“apple”与“apples”的BLEU得分为0,但在实际应用中他们应该被视为一致。这增加了挑战的难度。
技术方案
标题作为产品的简洁表示,需要满足三个基本要求:(1)吸引人的,(2)准确描述用户偏好,以及(3)准确传达关键信息。为此,该团队设计了两个模块:共同访问模块和分词对齐模块,使得生成的标题满足这三个理想属性。
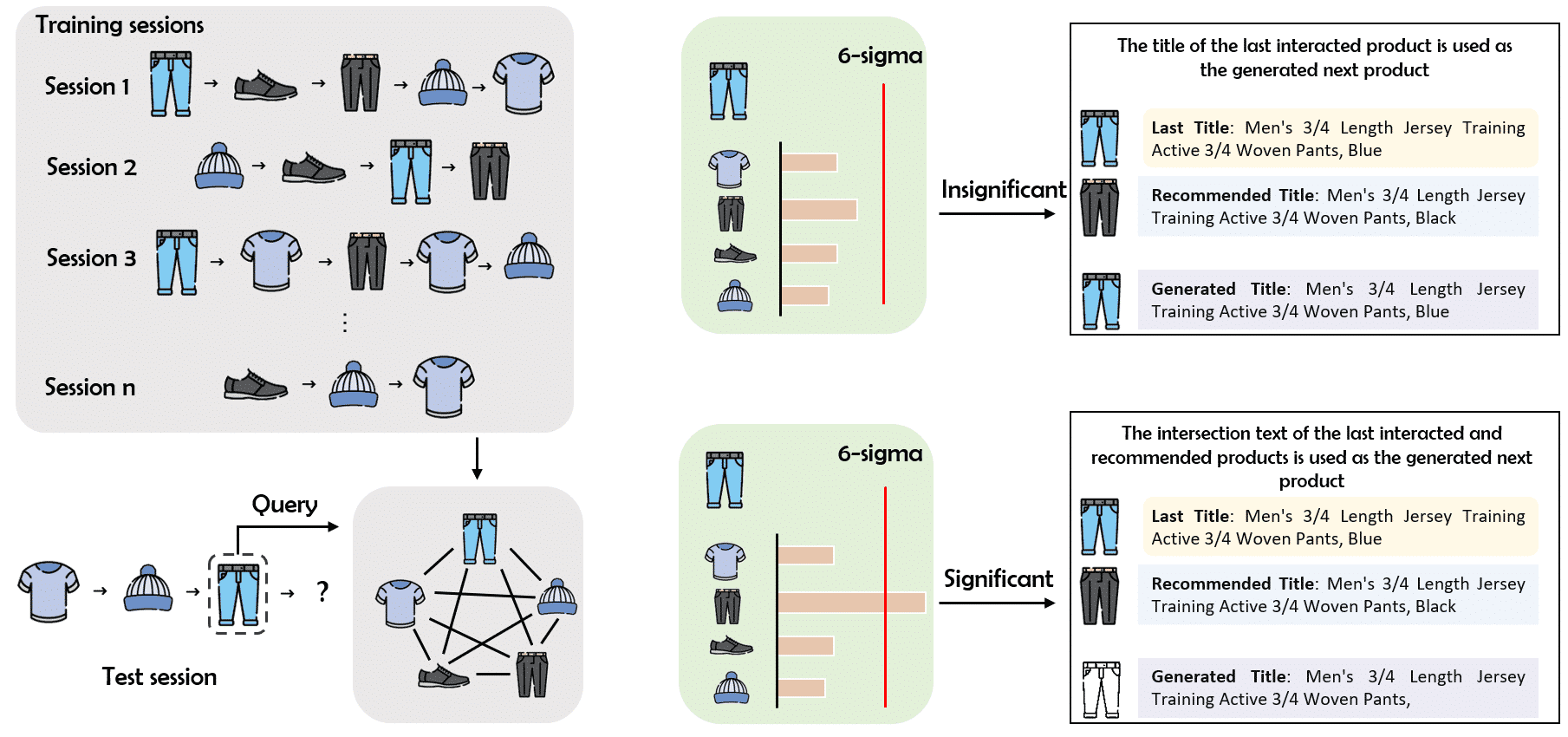 模型框架图
模型框架图
共同访问模块
直接生成新的标题可能无法保证它们具有吸引力。为此,从现有标题中选择候选标题用于生成下一个标题是一种解决方案。因此,一个表现良好的推荐系统是非常有必要的,这可以帮助系统更深入地了解用户偏好,从而制定各种个性化的标题。对于经典的基于会话的推荐系统,如SASRec[1]和GRU4Rec[2],虽然取得了令人满意的性能,但它们top-1产品的推荐得分往往过于自信,不管推荐正确与否。由于BLEU无法灵活捕获近似词的限制,那么即使推荐的产品和ground truth高度相似也可能显著降低BLEU得分。
为此,该团队使用一个简单、透明、推荐得分可区分的基于共同访问的模型,其直观的定义为一定时间间隔内同一用户点击两个产品的事件发生。考虑到会话中较早交互的产品的滞后性无法对最终产品的预测提供积极的帮助,在构建共访问图时,只提取每个会话最近的交互记录,并且,根据时间对连边的权重进行线性衰减。得到共同访问图后,为了避免错误预测导致BLEU指标的显著下降,只使用推荐得分较高的产品标题作为候选标题用于最终标题的生成。而对于得分较低的推荐标题将其忽略,直接选择最后一个交互的产品标题作为最终的预测。
分词对齐模块
虽然优先选择高置信度的标题来降低风险,但它们经常包含冗余的分词(例如尺寸、颜色等),这可能无法准确传达关键信息。该团队发现最近一个交互的产品标题和共同访问模块推荐的标题往往高度相似。因此,通过建立他们的交集可以移除非关键的分词,比如尺寸信息。另外,为了防止对齐后提取的分词太少而导致BLEU的惩罚过高的情况,引入了一个分词长度阈值来判断是否需要对分词对齐。
RecSys Challenge 2023 ”广告 CTR 预估“挑战赛
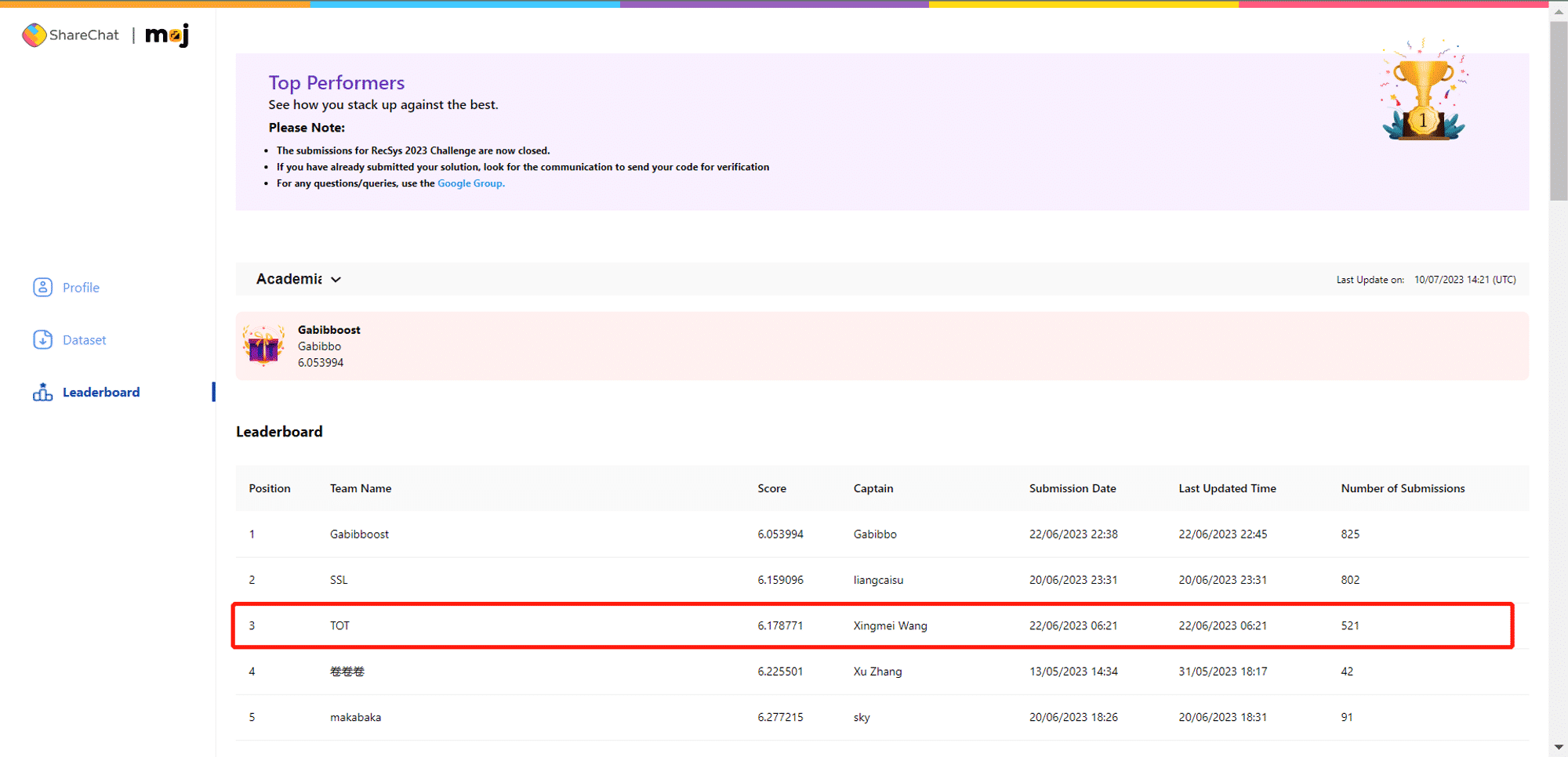 竞赛结果
竞赛结果
团队成员:王幸美、王岩开、连德富 方案论文:Xingmei Wang, Yankai Wang. A Simple and Robust Ensemble For Click-Through Rate Prediction[C]//RecSys Challenge 2023. 开源链接:https://github.com/pepsi2222/RecSys-Challenge-23
比赛介绍
Sharechat 组织的 RecSys Challenge 2023,旨在根据前 22 天用户和广告的交互数据预测第 23 天用户安装某广告的概率。每一条交互包含了时间、用户侧特征、广告特征、交互特征、是否点击和是否安装两个标签。在追求个性化的同时,比赛的数据集匿名化了所有特征,以鼓励保护用户隐私的 CTR 预估算法,因此几乎无法进行特征工程。评估指标采用了 Logloss.
技术方案
为了尽可能降低模型的复杂度、提高模型的可解释性,该团队在数据预处理时:1)将 out-of-vocabulary (OOV) 占比很低的数值型特征转换成类别特征;2)根据交互时间创造新特征”星期几“;3)过滤掉完全线性相关的多余特征。
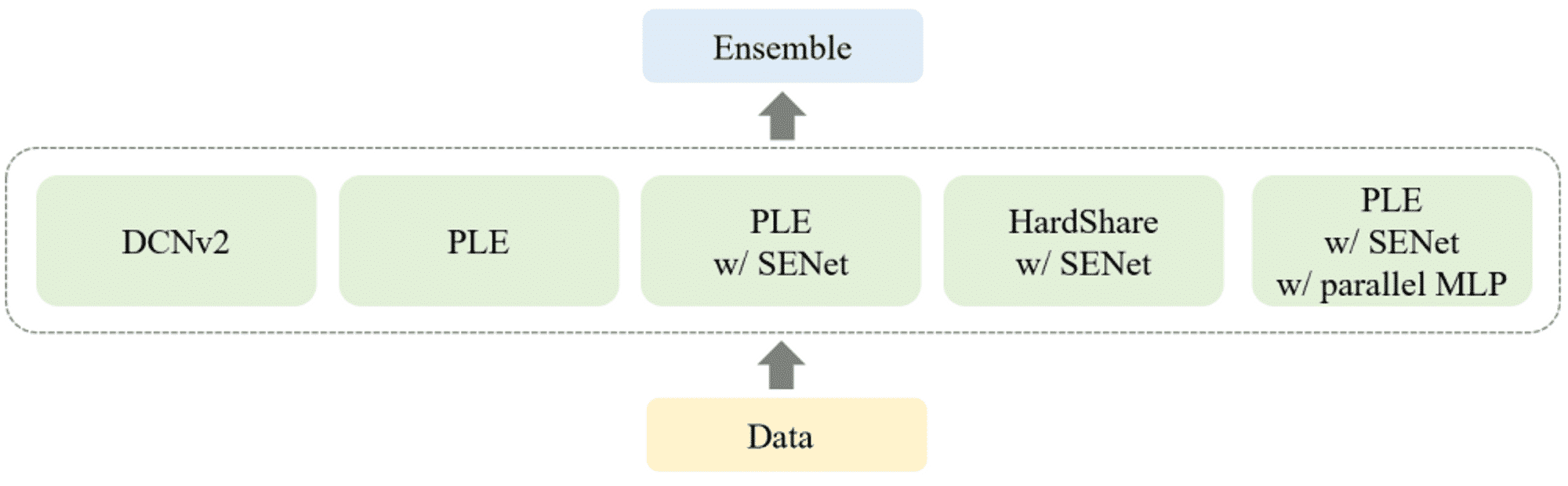 模型框架图
模型框架图
在模型设计上,采用了集成的方法,其中基学习器包括了单任务模型 DCNv2[5] 和多任务模型 PLE[7]、HardShare[6] 及其变种。在多任务模型中,结合 SqueezeExcitation Net (SENet)[8] 和 Parallel MLP 有助于提升性能。最终的集成采用了一种简单鲁棒的 Blending:去掉最大和最小的预测概率后再取平均。
参考文献
[1] Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
[2] Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
[3] Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1419–1428.
[4] Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. 2001. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th international conference on World Wide Web. 285–295.
[5] Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. 2021. Dcn v2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. In Proceedings of the web conference 2021. 1785–1797
[6] Sebastian Ruder. 2017. An overview of multi-task learning in deep neural networks. arXiv preprint arXiv:1706.05098 (2017).
[7] Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. 2020. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. In Proceedings of the 14th ACM Conference on Recommender Systems. 269–278.
[8] Jie Hu, Li Shen, and Gang Sun. 2018. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 7132–7141.




