



本文从服务机器人对视觉技术的需求入手,围绕口罩识别、人体姿态估计、物体识别等机器视觉技术在不同类型服务机器人中的研究与应用实践进行深度讲解,最后就优必选机器视觉技术在机器人中的未来研究方向给出自己的思考。
文章分三个部分:
1、服务机器人对视觉技术的需求
2、优必选机器视觉技术研究领域和应用实践
- 口罩识别在防疫机器人上的应用
- 人体姿态估计在教育机器人 Yanshee 上的应用
- 物体识别在家庭教育服务机器人悟空上的应用
3、优必选机器视觉技术未来研究方向
服务机器人对视觉技术的需求

优必选是全球领先的人工智能和人形机器人企业,旗下有面向不同领域和场景的服务机器人。上面一排最左边是智能巡检机器人 ATRIS,中间是 Walker,Walker 是优必选为实现“让机器人走进千家万户”这一目标迈出的坚实一步。右边分别是商用服务机器人 Cruzr 和室内智能巡检机器人 AIMBOT。下面一排从左到右分别是悟空机器人、Yanshee 和 Jimu 机器人,他们可以应用于家庭场景和教育领域,并且许多学校已经用 Yanshee 和 Jimu 践行 AI 教育。
要让机器人能够感知事件,通过视觉是必不可少的手段之一。通过视觉感知,让机器人检测到目标在哪里,识别是什么目标。比如机器人导航过程中,常常遇到一些人、车、植物或其他障碍物,目标检测是机器人做导航避障的一个重要手段。另外机器人与人交互过程中,能够识别人,估计人的姿态和手势,这也解决人机交互的一个必要技术。

服务机器人对视觉技术的常见的需求主要包括以下几方面:
第一个是视觉检测,希望把图像中的所有目标都检测出来并输出 bounding box 级别的结果;
第二个是跟踪,跟踪是把视频中各个科目相连生的目标关联起来,形成目标包括人或物体的轨迹;
第三个是姿态,广义来说,包括人脸的姿态,人体的姿态,还有手的姿态,能够准确计算人体的各个关键点和肢干点,就能把它们连接起来去描述这个人的姿态,在机器人与人交互过程中非常重要,通过姿态,机器人可以判断这个人是否有倾向与机器人交互,或者在机器交互表达什么样的内容;
最后一个是人脸识别,人脸识别落地的场景比较多,在机器人中希望它能够识别到个人。
优必选机器视觉技术研究领域和应用实践
下面介绍下优必选机器视觉技术的几个应用。
① 口罩识别在防疫机器人上的应用
首先是口罩识别,大家知道今年对全球人类来说都是比较不容易的一年。在过年放假回家之前,也没有想到年后要做口罩识别。以前口罩识别作为人脸的一个属性,分为戴口罩和没戴口罩。过完年后,突然发现疫情已经非常严重,国内有很多地方无法去现场办公,而是远程办公。
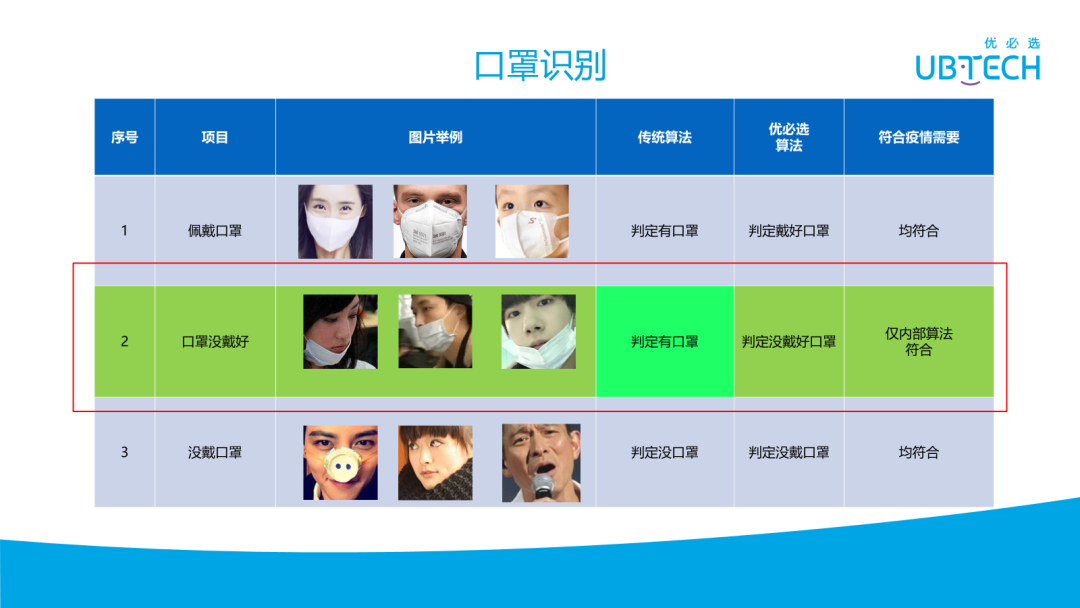
在接到口罩识别的需求时,首先是常规的口罩识别即戴口罩和没戴口罩。但在疫情这种情况下,会有一些很特殊的情况,就是很多人并未正确佩戴口罩。这也是有原因的,比如我在坐飞机时,带 N95 或普通的手术口罩,会感觉呼吸非常不容易,这时我觉得医生真的很伟大,因为他们需要长时间的带着口罩去工作去,为病人提供服务,对医生来说可以坚持,但普通人可能是不愿去坚持,于是就有很多人未正确佩戴口罩。这也是为什么需要做口罩识别,希望机器人在一些场景能够提醒用户,把口罩戴好,对于没戴的,更加要提醒让他们及时戴上口罩。
我们的算法与跟传统相比有很大区别,如上图中间一排,当鼻子或嘴露出来,或者鼻子和嘴都露出来时,这个人是有口罩的,只是没有带好。优必选的算法是把这种口罩的状态判断为没有戴好口罩,而常规的算法一般只能判断是否佩戴口罩,并没有将佩戴方式是否正确作为第三个状态来分类。
- 技术方案
刚接触到口罩识别的需求时,直观的认为口罩识别是对着一个相机拍一个视频,能够在不同状态下准确分析状态。比如露出鼻子,是没戴好口罩,整个都露出来就是没带口罩。
- 落地方案
当口罩落地到机器人时,会有些不一样的地方,因为落地到机器人上,是希望让机器人能够检测到未戴口罩或未正确佩戴口罩的人,做出语音的提醒,提醒用户及时把口罩戴好。

如上图右边的流程图显示,除了视频读入,人脸检测,更重要的是加姿态估计或语音提醒。那么为什么会加姿态估计?将在下面介绍,右边是一个落地的场景,当行人没戴口罩走到机器人面前时,机器人会发出报警音,提醒用户戴上口罩。

- 姿态估计方案
在口罩识别中加入姿态估计的一个重要因素是在口罩识别过程中,尤其是在短期内拿到的需求,大多数戴口罩和没戴口罩的人都是比较偏向正脸。如果要在各种角度的人脸下把口罩识别好,就面临在不同状态下去抓拍,采集大量的数据,这个工作量是巨大的。在侧脸状态下,脸部信息不全,容易造成误识,会使得产品的体验不是很好。为了减少这种情况,把姿态估计加进去,抓住人脸估计中的正脸,更准确的实现口罩的识别和精准推送。
对于姿态估计,优必选去年已经做了一个在机器人端的轻量级神经网络,用于姿态的精确估计。它可以在复杂的场景下做人脸的姿态估计,但是在口罩识别场景下,如果每一帧都要算精确的姿态估计,尤其是在人很多的情况下,对计算的考验是非常大的。为了避免这种情况,我们就做了一个姿态粗估计的方法,就是计算人双眼之间的距离与眼和嘴巴之间的距离,当正脸变侧脸时,双眼之间的距离会变小,而眼睛到嘴巴的距离不会有明显的变小,这样可以去区分出侧脸和正面。

- 人脸校准方案
在口罩落地时除了姿态外,还面临各种各样的场景,一个常见的场景是后脑勺,有时会碰到衣服、手等,都会被误检成人脸。人脸有时检测可能不全,如上图中的第四张图,由于人脸检测不全,口罩只露出一部分,在判断口罩时可能误认为是没戴口罩。为了改善产品体验,我们设计一个极其轻量的网络来做人脸的校准,通过对误检人脸的筛查,过滤被误检的人脸。如果 100 个人能够过滤 99%,那剩下的误检就非常少,可以极大的改善整个产品的体验。
综上所述,优必选的口罩检测技术,要求在动态场景不需要用户去配合,所以是一个零配合的场景。为了在机器人有限的算力下完成这些工作,用了轻量级的模型,同时根据实际中遇到一些情况,把产品提出了三分类的状态,就是识别戴好、没戴好和不戴。在实际应用过程中,发现人脸检测还有很多不完美的地方,通过优化误检的人脸带来的问题,改善体验。在侧脸情况下,发现口罩识别想要做到准确率在 99%以上还是非常难的,于是我们尽量抓住人脸的正脸,通过姿态判断来处理。最后一个是通过跟踪去重,一个人尽可能的只推送一个状态。
下面是一个落地的 demo 场景。当一个人或几个人走进来时,若没戴口罩用红框来表示,戴口罩用绿框表示。

- 测试结果
我们测试了很多轮,到最后一轮,把机器人放在楼下的大堂,收集 1000 多人的视频,并做到了零漏检,误检大概有 0.15%,口罩的误识大概有一两个佩戴的口罩的被认为是没戴口罩,而在漏识率中,所有没戴口罩的情况都能准确检测出来。
② 人体姿态估计在教育机器人 Yanshee 上的应用

人体姿态估计,可分为 2D 和 3D,也分为单人和多人。机器人绝大部分场景可能只有一个人或者少数几个人。在三维情况下,如上图所示,可以从 x 面即正面看到动作,同时侧面还有一个前后的动作。右上角是跑的一个视频,可以准确看到这些人的姿态变化。从广义的角度看,人体姿态估计是基于视觉的人体活动分析的技术之一。它对全身的关注研究叫做人体姿态,在人脸识别当中也有人脸姿态的需求,另外还有手部的姿态估计。这三个看起来是三个不同的,但实际背后的技术非常相似。
- 概述
就人体姿态估计本身而言,从最早的可能只有 14 个关键点到 17、18 个关键点,还有 25 个关键点。不同的研究人员可能是采用不同的方案,最多有 135 个关键点,就是把人体的所有的点即手、脸、还有脚都包括进来。点这么多对数据的要求也会非常大,实际中想要真正的用上其实也很困难。
- 面临挑战
人体姿态估计面临很多的挑战。第一个挑战是很多关键点可能看不到;第二个是很多人站在一起成为一群,那每个人的图像非常小,这时想要训练,如何标注也是一个非常难的课题;第三个难点是图像的分辨率,尤其是在人站的比较远时;第四个是在人机交互时,可能会遇到人体与机器人之间距离太近,使得机器人只看到人体的一部分,这时想要准确估计人的姿态点也是困难的。
总体而言,这些挑战是因为人体是柔性的,可能有各种姿态和形状。而在人体姿态上,任何一个部位的微小的变化,对整个人体姿态的影响是非常大的。另外一个是关键点受到衣服、视角的影响,可能换一些不同的衣服或者衣服跟背景颜色比较相似时,使得关键点的检测可能不准。第三个是面临的遮挡、光照等因素。在技术的取名时,大家注意到人体叫估计,所谓的估计就是有很多不可见的关系。在标注上可以看到学术界用的标注方法,有一些点是要注明出它的状态,有些是不可见不标注的,有些是不可见但标注的或者是可见并标注的,这些在训练当中是会有不同的策略去对待。
- 常见方法
最近几年比较热的是一些基于热图的方法,比如像卷积姿态机、Stacked Hourglass。卷积姿态机通过不同的 stage,计算出一些不同关键点,例如 15 个关键点的不同热图,从这些热图上再去找到它的关键点,然后通过后面的 stage,把这些关键点相互关联上。因为人体的关节点的相对的位置有一定的固定关系的,通过这种关联,可以减少误差。
2017 年,ICCV 和 CVPR 分别有 AlphaPose 和 Openpose 的技术。相应的数据集也有很多。AlphaPose 和 Openpose 可以在多人的场景去做姿态的估计。
这些方法当中大体的流程都是从一个带数据的处理到估计各个关节点热图,然后根据姿态的模型,去计算出热图,最后在计算出这些关键点的位置。在热图方法和直接回归方法中,回归方法可能提出的更早一些,现在人体姿态估计在热图的方法显示结果会好一些。

- 应用分析
人体的姿态估计有以下几个不同的应用,一个是人的异常行为识别,比如动作检测、打架或者打电话等这些行为可以通过姿态估计计算出来;还有一个是人体的动作模仿,人体的动作模仿就是让机器人模仿人的动作,左图是一个用计算机模拟机器人跟随人做动作的案例,右边是一个 AR 的视频,把人体的姿态计算出来,然后在上面把 AR 加上去;在教育的场景中,可以看哪些学生是在提笔写字或者举手;在一些特殊场景下,能够检测到摔倒等。
除了人体之外,手的姿态也可以准确的检测出来,它背后所用的技术是类似的。
我们用 Yanshee 机器人去做了一个动作的模仿,而 Yanshee 是一个基于 linux 的开源的软件,它可以支持多个传感器,最重要是它有 17 个肢体关节点的自由度,可以利用这些关节点来模人的动作。
③物体识别在家庭教育服务机器人悟空上的应用
最后来介绍下物体识别在家庭教育服务器人悟空上的应用。

我们的物体识别是基于检测的,物体检测和目标检测就是希望找出这个图像中所有感兴趣的目标,一般就是找出 bounding box,这样就可以确定它的位置,同时也会给出它的类别。由于很多物体可能有出现不同的姿态,会有各种遮挡,还有很多的不规则性,比如运动中可能会有模糊,或在不同的天气、光照条件下,摄像头所拍出来的图像也是千差万别。目标检测是现在 CV 里一个非常重要的技术,因为检测的结果直接影响后面的跟踪,或者姿态估计和其他的动作识别,还有行为的描述等效果,所以目标检测任务非常的具有挑战性。尤其是在机器人上去做检测,因为机器人所能具备的算力非常有限,它很难像学校实验室一样有强大的算力。

- 技术现状
目标检测技术主要分为 Two-Stage 算法和 One-Stage 算法。那 Two-Stage 算法以何凯明他们之前做的从 R-CNN 到 Fast R-CNN 再到 Faster R-CNN 这一系列的工作。所谓 Two-Stage 就是先提取 Region Proposal 出来,再去计算 CNN 的特征,分类这些 Region 属于哪一个目标,哪个物体。但是 Two-Stage 一般是比较慢的,因为它分了两部分。最近有很多的 One-Stage 算法不需要 Region Proposal 的阶段,直接通过一个阶段就能产生这个物体的类别和和位置,比较经典的包括有 YOLO、SSD、CornerNet 和 CenterNet。One-Stage 算法总体上它有一个主干网络去提取特征,然后再加一些检测头去计算我们所希望计算的一些数值。
在机器人端以悟空机器人为例,我们有很多需求,比如通用的物体识别,把物体放在悟空前面,希望悟空能够识别这些物体,通过一些语音交互,像跟悟空说:‘悟空这些是什么’,它能告诉我这是苹果还是橘子等;第二个应用是知识百科,常见的水果可能大家都能认识,但是有很多植物或动物,大多数人不能真正识别出来,希望悟空能够把它们识别出来,就相当于一个具有百科知识的机器人,能够让你想了解什么物体,它都帮你了解到;在家里面也可以用来教小孩;最后是可以用悟空来做编程,比如拖动积木的案例,能够预测对应的图像分类结果,返回对应的值。
在机器人上做的物体识别所面临的一个挑战,就是计算芯片相对于在学校的 GPU 相差很大。悟空只有一个八核的 ARM 结构处理器,存储也有限,在极少的资源下做物体识别是非常有挑战的;另外尽管处理器这么多,还不能全部占用,占用太多会出现可能发热的问题;除了物体识别外,可能还会有一些其他的任务要做,所以真正能给到的资源非常少。
- 算法架构
从算法层面,是在之前的 CenterNet 的基础上来做前两块的工作,在 CNN 特征提取这块尽量把网络轻量化,然后回归计算出的中心点、长宽、中心点坐标偏移,根据这三个数就会有一个物体框的位置。

- 挑战
在实际开发工作中,我们面临很多的挑战。由于要识别这些物体,首先面临的是数据不足;其次是物体可能有很多的子类,这些子类图片可以从互联网下载,也可自己去拍,但都很难找到又多又均衡的图片。如上图所示,右上角是个桃子,左边也是个桃子。当去识别桃子时,会发现这个左边可能出现两个框,它们非常接近且很大的重叠,一个框是识别是桃子,另一个是苹果。出现这种情况,就面临一个问题,它这到底是什么?
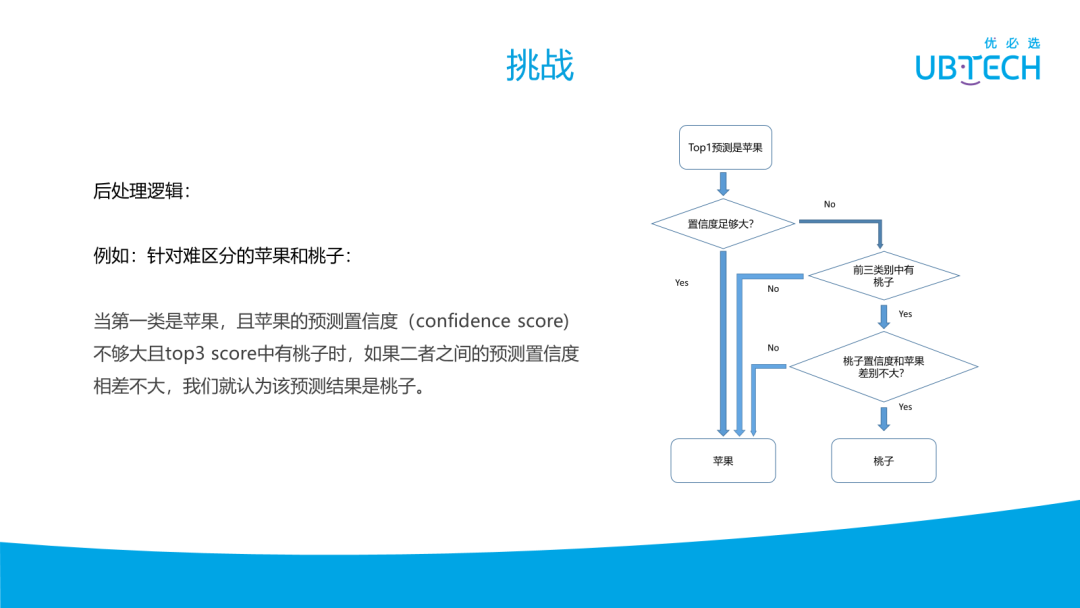
可以利用一些后验干预来做后处理,当算法检测到它可能是苹果或桃子时,若仅依靠苹果的置信度比桃子高,就认为是苹果其实不太对。正常情况下,应该是设一个阈值,超过这个阈值就不再比较哪个置信度更高就是哪个。可能由于数据的因故,拿一些苹果来测,很难被认为是桃子,有些桃子就会容易出被判断为是苹果,但桃子被判断苹果的时候,经常本身也会有一个对它是桃子的预测。根据这些设计了一个后处理逻辑,当预测的 Top1 是苹果时,而且置信度本身不是那么大,需要看看它的前几类有没有桃子,或者在相同的位置框里面有没有桃子,如果是有桃子,而且桃子的置信度也足够大,或者桃子跟苹果的置信度相差不是很大,其实很可能是桃子,我们不想把桃子给漏掉。
- 结果
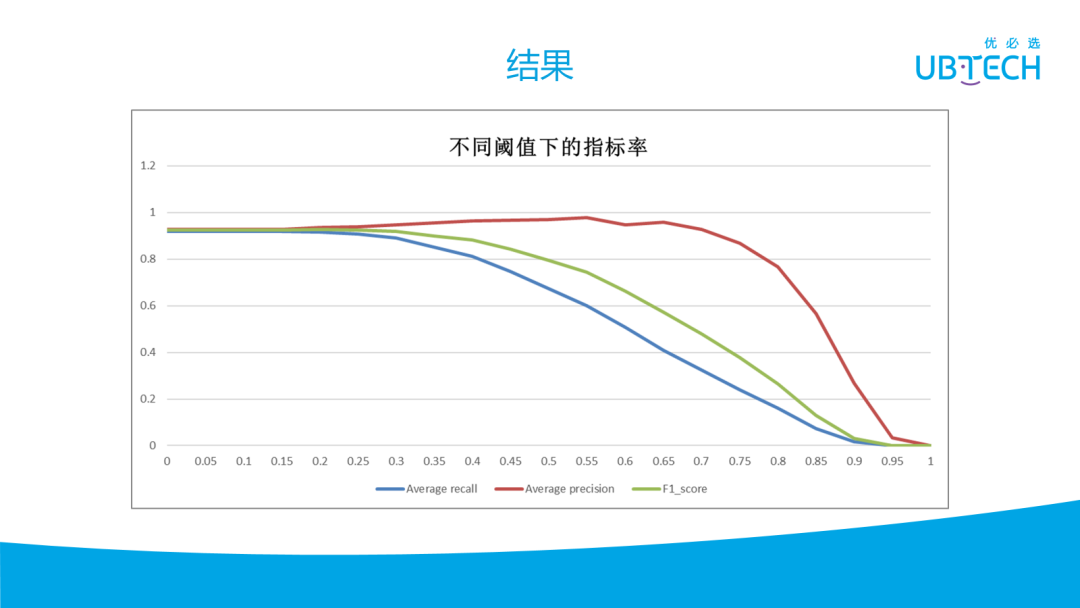
物体识别总体平均的 recall 在阈值为 0.2 或 0.3 左右,是比较推荐的,大概能识别 90%以上的不同物体。随着阈值的增加, precision 会增加,但 recall 会下降。

- 对比
上图是与外面开源的一些算法的对比,以花和草莓的识别为例,左上角在花很多时只画了一个大框,但是我们的算法画的是小框,这样更加符合日常的使用,当与机器人交互时,可能会有很少的花在,希望能把每朵都准确识别出来。对于草莓的识别,在我们的算法里,几乎每一个草莓都能识别出来,而左边的模型,很多草莓被漏掉了。
优必选机器视觉技术未来研究方向
介绍完三个技术的应用之后,来稍微介绍下机器视觉在未来的一些的研究方向。
机器人上要做的视觉技术非常多,远不止列的这几个。一个是视觉导航,现在激光导航面临很多的局限性,比如碰到黑色物体、玻璃或在特别空旷的区域,激光导航会有很多的问题。视觉导航就可能是一个很好的选择。但视觉导航也面临很多挑战,比如光线或天气都可能影响视觉导航的性能。有些场景可能是动态的,比如在很多的商场,每天的场景都不一样,可能有些柜台或者临时的柜台,每天放在不同的地方,这就使得如果通过建图的方式做视觉导航,每天都需要重新建图,这也是不现实的。
语义地图可能更加贴近人的体验,但是语义地图要实时的把场景里面的人和物还有各种物体识别出来,并同时在地图中把它们都构建起来是非常有挑战的;而机器人想要跟人一样,手眼协调功能是非常重要的,让机器人能够抓取各种各样的物体,也是我们现在正在做的一些事情。目前基于单帧图像的目标检测,效果已经很好了,但是对于视频分析,比如分析视频监控中一群人的行为,还面临很多的挑战。
这些方向可能是机器人视觉方向在将来急需的一些技术。

