




编辑 | 萝卜皮
在过去十年中,非法药物市场因秘密生产的名牌药物的激增而重塑。这些被称为新型精神活性物质(NPS)的药剂旨在模仿众所周知的滥用药物的生理作用,同时规避药物管制法律。新精神活性物质滥用的公共卫生负担迫使毒理学、警察和海关实验室在执法缉获样本和各类生物样本中对其进行筛查。然而,由于这些物质的化学多样性,以及它们在非法市场上出现的短暂性质,识别新兴的 NPS 非常困难。
不列颠哥伦比亚大学(University of British Columbia)、阿尔伯塔大学(University of Alberta)等机构的研究人员合作,研发了 DarkNPS;这是一种支持深度学习的方法,可仅使用质谱数据自动阐明身份不明的设计药物的结构。该方法采用深度生成模型来学习未观察到的结构的统计概率分布,研究人员将其称为结构先验。
实验结果表明,结构先验允许 DarkNPS 以 51% 的准确度和 86% 的前 10 名准确度阐明未识别 NPS 的确切化学结构。该生成方法有可能使质谱法常规分析的其他类型小分子的从头结构解析成为可能。
该研究以「A deep generative model enables automated structure elucidation of novel psychoactive substances」为题,于 2021 年 11 月 15 日发布在《Nature Machine Intelligence》。

背景
过去十年见证了新精神活性物质(NPS)的可用性和爆炸性增加,也称为「设计药物」或「合法兴奋剂」。NPSs 通常是通过对现有滥用药物的化学结构稍加修改而产生的,产生的衍生物可以规避药物管制立法,同时保留其精神活性。众所周知的 NPS 的例子包括合成大麻素、合成卡西酮、迷幻色胺和苯乙胺,以及合成阿片类药物。
NPS 是由不良化学家秘密合成的,他们挖掘科学和专利文献,以识别针对与现有精神活性药物相同的受体的化合物。这些化学家对这些化合物分布缺乏控制,意味着新的 NPS 正在以每周大约一种化合物的速度不断进入「灰色市场」。
与此同时,成熟的药物可能会因立法而迅速从市场上消失。NPS 的药理学和毒理学尚未得到很好的表征,其中许多与危及生命的中毒症和死亡有关。因此,陶醉于 NPS 的患者给医疗保健系统带来了沉重的负担。这种公共卫生负担迫使全球的法医实验室在执法缉获的样本中筛查 NPS。然而,这些物质的化学多样性,以及它们在非法市场上出现的转瞬即逝的性质,给新化合物的检测和鉴定带来了极大困难。
由于多种原因,在缉获或生物样本中识别新的设计药物具有挑战性。首先是候选 NPS 之间的高度结构相似性,它们通常是来自同一药物化学系列的类似物。第二个挑战是新化合物进入灰色市场的速度太快,这需要为以前未知的物质开发新的检测方法。检测开发需要大量的时间和精力,而 NPS 固有的新颖性意味着对于最近进入市场的 NPS,很少有分析参考材料。
当前,已经开发了许多分析方法来克服这些挑战。从历史上看,筛选主要通过免疫化学方法完成,但这些方法受到灵敏度低、无法提供成分解析的药物谱以及建立新检测所需的时间和精力的限制。
最近,质谱(MS)已成为 NPS 检测和识别的主要方法。高分辨率 MS(HR-MS)可以为给定分析物提供高度准确的质量测量值,缩小潜在候选物的列表,并允许与参考数据库进行比较。串联质谱(MS/MS)以诊断性子离子的形式提供附加信息,从而实现更高可信度的分子鉴定。然而,MS 方法的一个主要缺点是,为了通过其精确质量或串联质谱来识别 NPS,研究人员最低限度地要求其化学结构存在于参考数据库中。这对识别刚刚出现在市场上的新设计药物构成了障碍。
阐明这些新化合物的完整化学结构通常被认为需要正交技术——最常见的是核磁共振光谱。然而,NMR 的较低灵敏度需要大量的 NPS 材料作为输入。
在实践中,即使冷冻探针技术可以提高其灵敏度,核磁共振也只能应用于执法部门的缉获,从中可以获得足够数量的物质。出于同样的原因,在疑似 NPS 中毒的情况下,核磁共振不能用于筛查人体组织。
简介
研究人员介绍了 DarkNPS,这是一个支持深度学习的系统,可仅使用 MS 数据自动阐明未识别 NPS 的化学结构。该方法基于使用化学结构的深度生成模型。这个家族的模型在化学和深度学习领域引起了极大的关注,因为它们有可能按需生成具有任意物理化学或生物特性的分子,从而解决所谓的「逆向设计」问题。
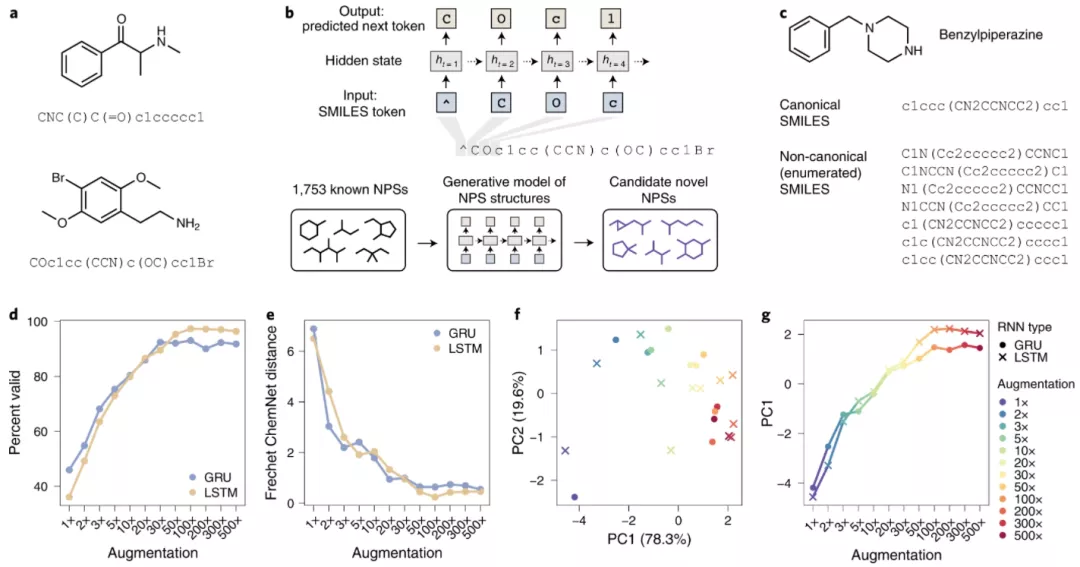
图示:新型精神活性物质的深度生成模型。(来源:论文)
这项工作的大部分内容集中在产生对特定受体有活性的配体的可能性上。在这里,研究人员寻求生成与一种或多种分析测量特性相匹配的类 NPS 分子。通过使用适用于低数据机制的策略来实现这一点,从仅约 1,700 个示例中学习设计药物的强大生成模型。
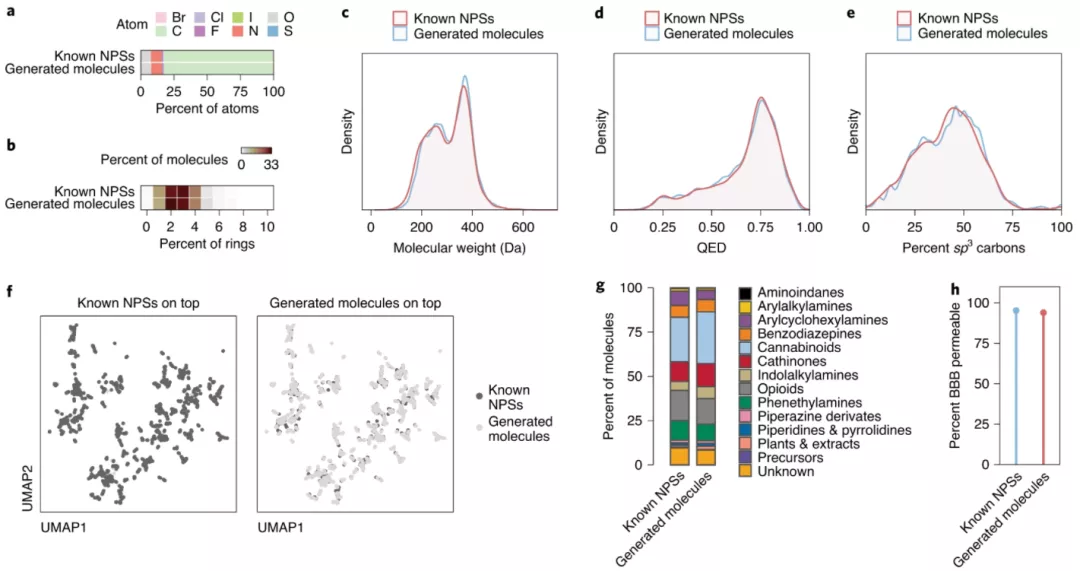
图示:生成的分子与已知的设计药物非常相似。(来源:论文)
从这个模型中采样然后随机生成新分子,这些分子与现有的设计药物填充相同的化学空间。研究人员使用一组保留的 194 个 NPS 来验证 DarkNPS,这些 NPS 在检验后由法医实验室接收,这表明研究人员的模型成功预测了随后出现在非法市场上的 90% 以上的 NPS。
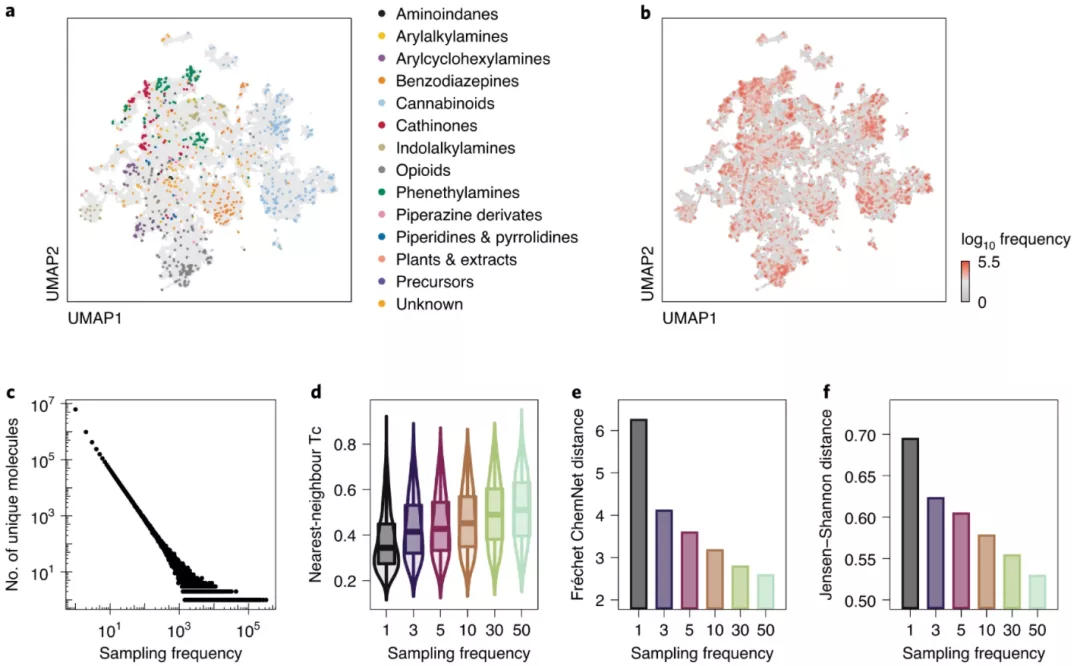
图示:采样频率定义了不可见分子的结构先验。(来源:论文)
因此,从模型中采样新分子的频率可用于建议最有可能解释准确质量测量的化学结构。生成的结构与 MS/MS 数据的整合进一步提高了结构解析的准确性。
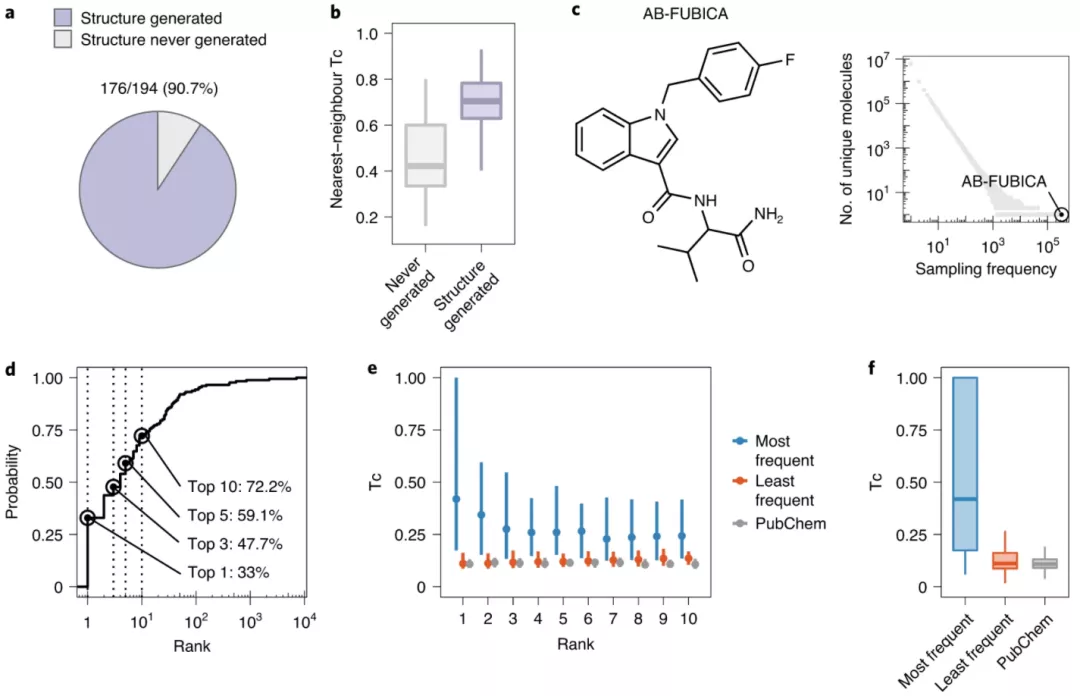
图示:未识别的 NPS 的自动结构解析。(来源:论文)
讨论
这项工作成功的关键是研究人员能够从少量示例中学习强大的化学结构生成模型。为了实现这一目标,研究人员严重依赖于从研究人员最近的基准分析中确定的有限训练数据中学习强大的生成模型的策略。
在该研究中,研究人员试图通过对来自四个化学数据库的 SMILES 字符串的随机样本训练超过 8,500 种不同的语言模型,系统地剖析在低数据机制中学习稳健生成模型的要求。研究人员系统地改变了模型训练的各个方面,从数据增强和分子表示到模型架构和超参数。研究人员的实验结构还允许研究人员对用于评估生成模型本身的指标进行基准测试,并确定为模型开发提供良好基础的指标子集。
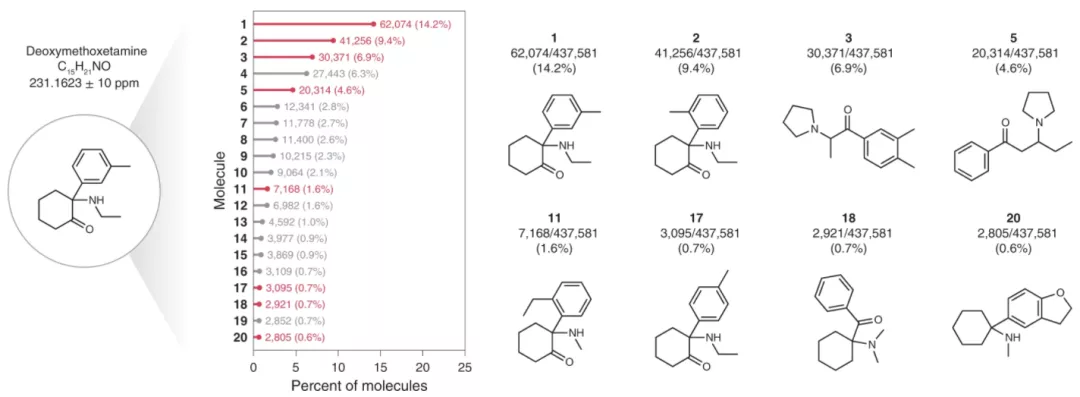
图示:在设计者解离脱氧甲氧塞胺之前应用结构。(来源:论文)
在这里,研究人员利用本研究中开发的见解从仅约 1,700 个已知 NPS 中训练了一个出色的生成模型。该数据集比传统上用于训练生成模型的数据集小几个数量级。研究人员的模型在如此少量的训练数据中表现出惊人的良好性能,这可能是许多因素的基础。非规范 SMILES 枚举的数据增强对模型性能产生了巨大影响,与之前的结果一致。另一个可能促成研究人员成功的因素是 NPS 的化学空间相对均匀。这一观点与研究人员的发现一致,即当训练集的多样性较低时,生成模型更有可能在低数据环境中取得成功,并表明可能为许多具有生物医学兴趣的受限化学空间学习生成模型。
研究人员的方法的一个局限性在于,它需要研究人员从生成模型中抽取一个非常大的样本,以将每个独特分子出现在模型输出中的频率制成表格。这是由于 SMILES 格式的冗余(即,许多不同的 SMILES 字符串可以对应于同一个分子)以及模型事先不知道给定 SMILES 字符串在生成时的质量是多少的事实 仍在进行中。
研究人员发现 10 亿个 SMILES 字符串的样本大小在化学空间覆盖率和计算要求之间取得了合理的平衡,并且足以获得对采样频率的可靠估计。然而,可以想象,未来的努力可以通过根据一种或多种实验观察到的特性调节分子生成来提高计算效率。
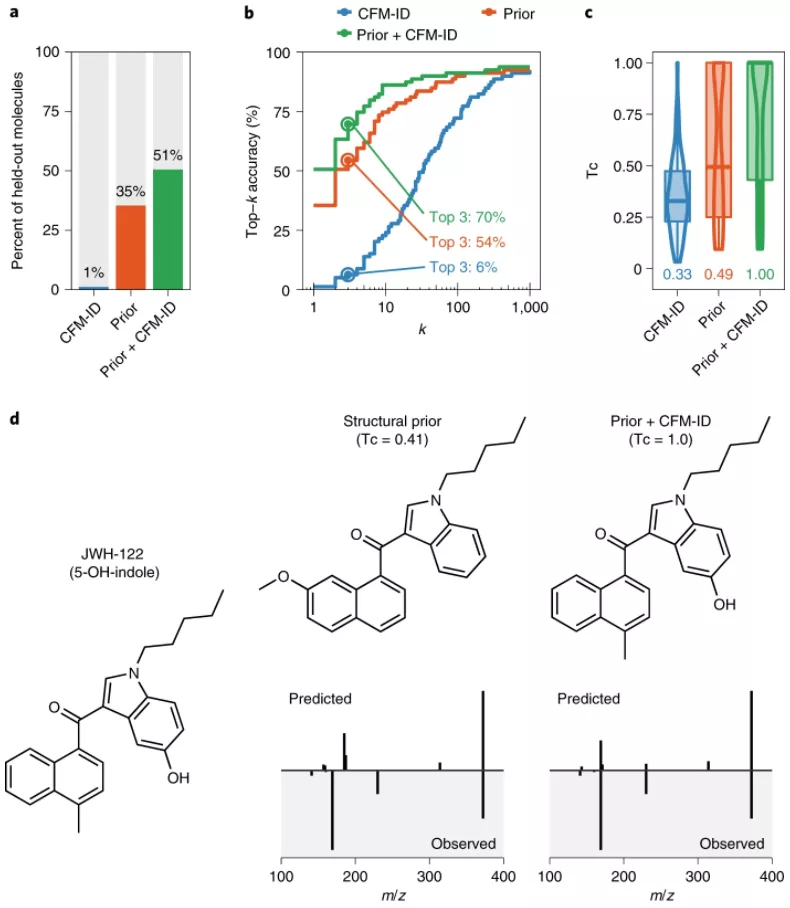
图示:使用 MS/MS 进行高可信度结构解析。(来源:论文)
结语
尽管如此,UBC 模型由新型精神活性物质数据中心安全分发,已经被美国缉毒署、联合国毒品和犯罪办公室、欧洲毒品和毒瘾监测中心以及德国联邦刑事警察办公室使用。
「现在有一个化学『暗物质』的完整世界,就在我们的指尖之外。我认为正确的人工智能工具有一个巨大的机会来照亮这个未知的化学世界。」该研究的主要负责人 Skinnider 博士说。
论文链接:https://www.nature.com/articles/s42256-021-00407-x
相关报道:https://techxplore.com/news/2021-11-drugs.html
