




作者:春ying
来源:知乎
自动调优其实是编译器工作的一部分。编译器的前端解析高级语言,中端做相应的优化(自动调优在这个阶段),后端生成目标硬件代码。目前有不少研究团队在自动调优方向开展工作,学术界也出现了一些自动调优的成果,但往往被吐槽自动调优没有手工优化的效果好,对此我的看法是:目前自动调优整体属于研究探索期,学术界还在做不同的尝试,调优效果会在这个阶段慢慢提高。目前的自动调优可以解决的问题是:从0%到80%的优化,对于从没有优化经验的,用自动调优工具可以快速地达到一个不错的效果。
这篇文章会大致讲讲自动调优的主要模块,各个模块的内容,以及一些常见的问题和可展开研究的方向。本文可为大家学习和了解自动优化技术做参考。
自动调优模块主要负责自动搜索出目标硬件平台上算子的优化策略实现。
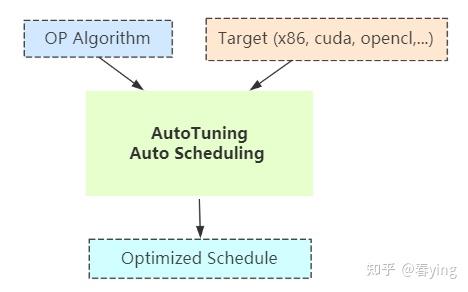
输入:
- Op Algorithm description: 算子的算法描述
- Target: 执行该算子的目标硬件
输出:
- Optimized Schedule: 该算子的优化的调度策略实现
一般的自动调优可以分为以下两个模块:搜索模块和评估模块。
- 搜索模块(Space exploration):
- beam search
- MCTS(Monte Carlo Tree Search)
- Reinforce learning Tuning
- 评估模块(Evaluation)
- cost estimation(基于cost model)
- correctness check
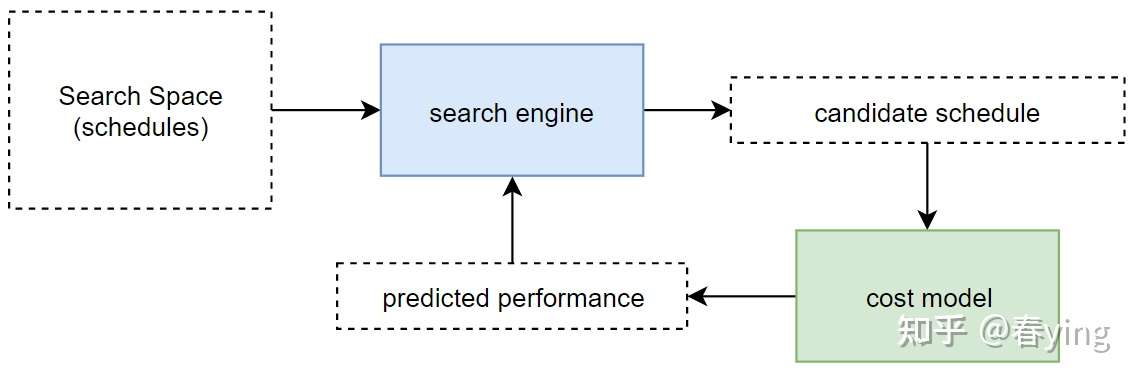
在自动搜索模块,目前相关研究的论文尝试不同的搜索算法:贪婪搜索算法, 束搜索(Beam Search), 蒙特卡洛树搜索(MCT), 强化学习(Reinforce Learning),遗传算法(Genetic Algorithm)等方法来搜索最优的schedule。在搜索空间有限的情况下,这些启发式算法之间的区别更多是搜索效率(即多快找到搜索空间中的较优解),并不能对调优效果起到决定性的作用。影响调优效果的好坏的更关键因素是,如何自动生成高质量的candidate schedule,也就是搜索空间的生成,是一项值得研究的关键工作。
在评估模块,cost model是一个研究方向,可用神经网络/机器学习的方法来预测性能。但无论是机器学习模型(xgboost),还是CNN模型,还是LSTM模型,都不是最关键的因素,关键是给定algorithm+schedule,如何对这个输入进行表征(representation/featurization),抽取出能有效表征其计算量/访存相关的信息量,是评估性能的一个关键环节。
有这么一句话在业界广泛流传:“对于一个机器学习问题,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”
所以,对于自动调优的问题,要想自动调优的结果有所突破,一个是数据(搜索空间),一个是特征工程(从原始数据中的找出/构建出一些具有性能优化意义的特征,这就需要有一定优化经验的优化工程师来思考)。剩下的搜索算法/cost model的模型选择,仅仅是逼近上限而已。
自动调优相关问题 & 可以展开研究的工作:
- 搜索空间如何生成?如何从零生成schedule? 生成schedule的思路是什么?
一般来说,生成schedule可以从算法描述(algorithm expression)切入,把计算过程分为多个stage/func,每个stage有各自的schedule primitive, 每个schedule primitive有不同的参数;显然,直接暴力列举出所有可能是schedule是不现实,会导致搜索空间过大,而且生成的schedule可能大部分不可用/性能一般,我们希望能高效地生成schedule, 思路可以分层级(multi-level)进行,从粗粒度到细粒度进行(Coarse-to-fine), 这个方向后续文章进行专门讲解。
2. cost model的训练数据是什么?没有足够的数据怎么办?
从上面的流程图可以看出cost model的输入输出,训练数据应该 (algorithm+schedule, performance)。没有足够的训练数据可以生成随机的程序和随机生成相应的schedule。
3. 为什么要用cost model,为什么不直接在硬件上预测性能呢?
使用cost model的目的是加速性能预测,给定一个algorithm, 可能有大量的candidate schedules需要评估性能,直接在硬件上评估性能耗时长,希望可以通过cost model模型快速评估性能。而采用神经网络/机器学习模型的原因和好处是,计算机硬件模型是相当复杂的(多层级存储结构,乱序执行等),使用一个简单的手工设计模型,比较难覆盖计算机硬件的复杂性从而比较难达到比较理想的性能预估。
4. 给定一个algorithm+schedule,可以用什么来表征?也就是如何作特征(featurization)?
- operation count: 加减乘除计算量的统计
- memory access: 数据访问/存储相关的
- loop:循环遍历相关的
- parallel: 并行相关的
其他,待补充
5. 自动调优的前提?
自动调优的前提是,已经有抽象好的schedule原语,如果面对新的硬件/算法没有比较合适的schedule原语,那么就需要根据硬件特性/优化经验抽象出新的schedule primitive, 比如:适配DSP/NPU/FPGA,可能需要单独抽象一个针对dma数据搬运的schedule原语,再通过自动调优指导在哪个阶段搬运数据,每次搬运多少数据。



