




除了在桌面处理器力推8核16线程处理器之外,在服务器市场上还推出了32核64线程处理器,前不久更推出了7nm的64核128线程“罗马”处理器,而AMD成为多核狂魔的背后是巧妙地利用了MCM多芯片模块技术,这也是大家调侃的胶水多核技术。本文由机器之心经授权转载自超能课堂,未经授权禁止二次转载。
从2017年到现在,不到两年时间里X86处理器行业的变化要比过去五年都要大,标志性事件就是AMD重返高性能处理器市场,除了在桌面处理器力推8核16线程处理器之外,在服务器市场上还推出了32核64线程处理器,前不久更推出了7nm的64核128线程“罗马”处理器,而AMD成为多核狂魔的背后是巧妙地利用了MCM多芯片模块技术,这也是大家调侃的胶水多核技术。

双核Pentium D时代,大家听到胶水多核就一脸鄙夷,不过2018年的今天,不仅是AMD在使用胶水多核技术,去年还在用胶水多核延迟高、性能差等缺点打击AMD EPYC处理器的英特尔今年也推出了胶水多核的48核处理器,未来还会把胶水多核技术发扬光大。
胶水多核到底好不好?这个事不是简单一句话能说明的,今天的超能课堂里我们就来聊聊MCM胶水多核技术的过去及未来。
摩尔定律失效,提升频率、增加核心之路不容易
对CPU处理器来说,人们追求的不外乎三点——性能越来越高、功耗越来越低、价格越来越便宜,定价这事不仅跟技术有关,还跟厂商的商业策略有关,这个问题不是技术能解释的,但是性能、功耗这事跟技术是直接关联,其中性能提升又是最重要的。
 消费级的英特尔CPU已经做到18核
消费级的英特尔CPU已经做到18核
在现有的条件下,提高CPU性能也只有两个方向了,一个是提高CPU运行频率,一个是增加CPU核心数,但是如今的半导体技术面临瓶颈,这两个件事都不容易,特别是同时有需求的情况下,因为大家现在既需要高频CPU,也需要多核CPU,这样就更犯难了。

28核Skylake-SP处理器架构已经很复杂,同时核心面积高达698mm2
这两年中在AMD的“帮助”下,英特尔已经加快了多核处理器的提升水平,去年之前桌面最多才是10核20线程,2017年就推出了18核36线程的Core i9-7980XE处理器,而服务器产品线上推出了28核56线程的Skylake-SP处理器,但是英特尔付出的代价也是相当大的,28核处理器采用了XCC架构布局,依然复杂无比,而且核心面积达到698mm2,而普通的桌面4核、6核处理器核心面积还在100-200mm2之间。
很显然,如果我们需要更多的CPU核心,那么核心面积势必要增大,那么核心面积增大有什么坏处呢?这个问题完整回答起来需要很长,最简单的解释就是在同样的制程工艺及晶圆上,芯片核心面积越大,产出越低,而且大核心更容易出现瑕疵,导致产能/良率进一步降低。
 核心面积大小对产能/良率的影响(图片来源)上面这个就是Stack Exchange上有人回答图像传感器为什么不做大面积的解答,芯片面积越小,晶圆利用率就越充分,良率越高,浪费就越少,成本就更低,而核心面积越大,浪费就越大,良率会下降。虽然例子是图形传感器的,不过对所有的半导体芯片来说都是如此。
核心面积大小对产能/良率的影响(图片来源)上面这个就是Stack Exchange上有人回答图像传感器为什么不做大面积的解答,芯片面积越小,晶圆利用率就越充分,良率越高,浪费就越少,成本就更低,而核心面积越大,浪费就越大,良率会下降。虽然例子是图形传感器的,不过对所有的半导体芯片来说都是如此。
有人要说了,更先进的工艺不是有助于提高频率、降低功耗、减少核心面积吗?没错,这就是摩尔定律的作用了,半导体厂商只要提高工艺技术,确实能让CPU的性能及核心面积受益,但是问题是摩尔定律早就失效了,也不是现在的14nm、10nm工艺失效的,严格意义上的摩尔定律在28nm之后就失效了——对于这一点,英特尔一直没有公开承认,但是从半导体业界多数厂商以及现有芯片的实际表现来看,摩尔定律这几年真的没用了,先进工艺带来的晶体管密度、性能等提升越来越小。

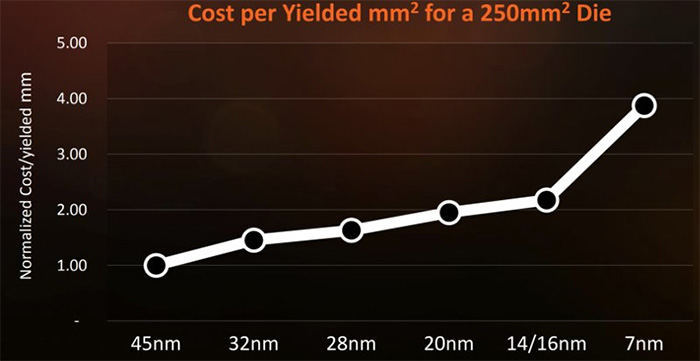
另一方面,先进工艺的研发、制造成本也在提升,这个成本提升是针对整体成本来说,特别是在28nm之后,从14/16nm工艺进入到7nm节点更是一次成本大提升。AMD提到了一个例子,以制造同样250mm2的晶圆核心为例子,对比了45nm到7nm工艺的成本,45nm工艺的成本为100%基准的话,28nm工艺的成本大概是1.8,20nm节点是2.0,14/16nm节点略高于2.0,但是到了7nm节点,成本就增长到了4.0,相比现在的14/16nm工艺成本翻倍。
根据专业的Semiengingeering网站之前刊发过一篇文章,28nm节点上开发芯片只要5130万美元投入,16nm节点需要1亿美元,7nm节点需要2.97亿美元。
即便不说先进工艺的巨额投资问题,但是从技术上来说10nm及以下的工艺就难多了,英特尔迄今都没有能量产10nm工艺呢,台积电、三星虽然做到了7nm级别,但是工艺水平及用途跟这里所说的高性能处理器还有点距离,总之指望先进工艺解决CPU频率及核心面积的问题也是不行的,这条路越来越难。
单打不行就群殴,MCM多芯片重新受宠
在半导体工艺逐渐逼近物理极限的情况下,指望未来的7nm、5nm甚至3nm工艺解救处理器是不太可能了,不过我们上面所说的种种弊端还是针对的单片电路(monolithic)的,既然单一芯片不容易提升,那就来多个芯片吧,这就是MCM(multi-chip module,多芯片模块)设计了,这种设计也就是被大家调侃的胶水多核。
MCM多芯片模块也不是什么新鲜玩意了,该技术也有数十年历史了,这么多年的发展也衍生出了诸多不同的MCM多芯片技术,所以尽管看起来都是“胶水多核”,但是不同的“胶水”效果也是不一样的,芯片封装技术多年来也是在不断进步的。
 图片来源
图片来源
至于AMD、英特尔两家公司中,英特尔还是最早应用MCM胶水多核的,早在Pentium Pro处理器上就使用过MCM封装技术,不过大家熟悉的可能还是Pentium D双核的胶水,那个年代为了抢先推出双核处理器,英特尔不得不在Presler架构的P4上用了MCM胶水技术,抢到了双核首发的荣誉。
当然,Pentium D双核在市场上的表现也不尽如人意,但这跟MCM胶水多核关系不大,更多地还是Pentium架构不给力的锅,MCM只是加剧了大家的不满。
之后英特尔及AMD在处理器架构上都极少使用MCM技术了,继续着原生多核架构,毕竟这种架构本来就应该是多核处理器应有的设计,不过随着CPU核心数逐渐从个位数提升到十位数范围,monolithic多核心的局限越来越大,不光是前面所说的制造难度大、良率低的问题,也因为它不够灵活,因为处理器除了核心数量之外,还要考虑到内存通道、PCIe通道等IO核心的搭配,如前面的Skylake-SP架构所示,为了配合不同核心的处理器,英特尔在它上面使用了XCC、LCC、HCC三种不同的内部架构,这样做无疑是增加了芯片的复杂性。

单芯片的设计越来越复杂、越来越昂贵,财大气粗而且有工艺优势的英特尔或许还能走下去,但是AMD不行,AMD不论是桌面处理器还是服务器处理器还得要跟英特尔打价格战,核心更多、价格更低是他们的武器,所以不可能再走单芯片的路线了,在Ryzen锐龙及EPYC霄龙处理器上AMD也用上了MCM多芯片模块。
在这种架构中,AMD将两组CCX单元作为一个模块做成了8核16线程处理器,这就是桌面版的锐龙7处理器,而第一代EPYC处理器最多32核64线程,其内部封装了是4个8核模块,详细的技术介绍我们之前的首发评测中做过解答,这里不赘述,我们就来看看AMD为什么这么做。

答案很简单——省钱。对于这个问题,AMD在EPYC架构中对比了MCM与Monolithic两种思路设计32核处理器的优劣,如果使用原生32核架构,核心面积只有777mm2,而现在的MCM多核芯片架构使用了4个213mm2的模块,核心总面积是852mm2,与单芯片相比是浪费了10%左右的核心面积。
但是制造4个213mm2的小核心处理器比制造1个777mm2的大核心容易多了,后者的良率太低了,低到多少呢?AMD今年公布过相关数据,完整的32核处理器良率不到17%,这样的代价是AMD承受不起的。

MCM设计除了会浪费部分核心面积之外,还有延迟问题,毕竟原生的多核心之间通讯要比外部芯片之间通讯距离短多了,这也是为什么锐龙处理器之前被人诟病过内存延迟的问题,但即便有这两个缺点,AMD还是把MCM设计发扬光大了,光是减少40%的芯片制造、测试成本就足够驳倒负面了,况且延迟等问题还可以用过别的手段缓解下,不造成明显影响就没事了。
 英特尔之前还表示AMD的MCM模块有性能及延迟问题
英特尔之前还表示AMD的MCM模块有性能及延迟问题
相比AMD转向MCM设计,英特尔近年来一直坚持原生多核设计,为此英特尔的首席架构师早前还专门写文章Diss胶水多核一番,表示原生多核优点多多,性能上没妥协,胶水多核就....但是这番话没多久,英特尔自己也推出了一个胶水多核——Cascade Lake-AP 48核处理器,它实际上是两个24核的Cascade Lake处理器通过MCM方式组合出来的,也不是原生48核。

英特尔推Cascade Lake-AP 48核处理器显然是要应急,虽然他们的28核处理器性能不比AMD的32核处理器差,但是价格贵很多,而且AMD今年还推出了64核架构的7nm罗马处理器,进一步拉开了与英特尔Xeon处理器之间的核心数差距,而英特尔2020年才有可能拿出10nm工艺的服务器芯片,但也难生产出原生64核的处理器,上胶水多核是迟早的事。
殊途同归,AMD、英特尔同时走向异构MCM之路
MCM胶水多核就只有现在这个样子了吗?并不是,AMD前不久宣布了7nm Zen 2架构罗马处理器,它最大的特点就是将CPU核心数提升到了64核128线程,比现在又翻了一倍,多核狂魔名不虚传。为了实现最多64核128线程的设计,AMD是会继续MCM胶水多核,不过这次的多核架MCM又不一样了。

从AMD公布的信息来看,7nm罗马处理器的MCM是8+1架构,很有众星捧月的感觉。在这个MCM多芯片架构中,AMD将CPU内核与IO单元分离,四周的8个小核心是纯CPU内核,而DDR内存控制器、PCIe控制器、IF控制器等IO单元单独做成了一个核心。

除了CPU内核与IO单元分离,7nm罗马处理器的还使用了不同工艺——核心的IO单元是14nm工艺的,GF代工的,而四周的CPU核心是7nm工艺的,台积电代工的。这样做也是为了降低成本,因为IO单元并不需要那么先进的制程工艺。

AMD在罗马处理器上的MCM结构让人联想到了英特尔之前的EMIB多芯片封装技术,二者在这方面可以说是异曲同工,殊途同归,都是在一个处理器封装内集成不同工艺的核心,英特尔的EMIB封装中CPU核心、核显可以是10nm的,通讯及其他IP核心可以用14nm甚至22nm工艺。

此外,英特尔还对比过EMIB封装与传统2.5封装的优缺点,表示EMIB技术具有正常的封装良率、不需要额外的工艺、设计简单等优点。
总结:MCM胶水多核或许是未来处理器的常态
从被人调侃到重获重视,MCM多芯片模块这么多年来又重新成为多核处理器的有力武器,特别是在核心数超过的服务器处理器上。另一方面,如今的MCM多芯片设计在技术水平上也跟当年简单粗暴的胶水多核不一样了,主要担心的延迟问题上,英特尔之前提到他们的EMIB技术相比单片电路的延迟只增加了10%,而别的技术方案中延迟甚至会增加50%之多。
不过MCM多芯片技术对主流桌面处理器影响就没这么大了,未来两年高端桌面处理器应该或是8核16线程为主,所以AMD下一代的锐龙3000桌面处理器是否还会使用核心、IO分离的设计很值得关注。
本文由机器之心经授权转载自超能课堂,未经授权禁止二次转载。