



<REASONING ABOUT ENTAILMENT WITH NEURAL ATTENTION>
1. Introduce LSTM
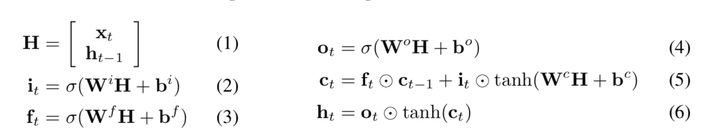
2. LSTMs can readily be used for RTE by independently encoding the premise and hypothesis as dense vectors and taking their concatenation as input to an MLP classifier. This demonstrates that LSTMs can learn semantically rich sentence representations that are suitable for determining textual entailment.
3. Conditional Encoding
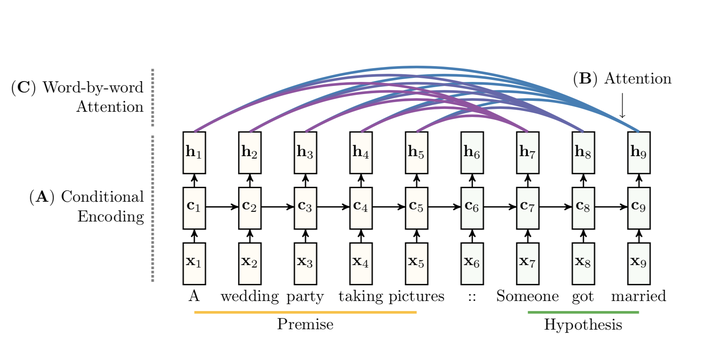
See part A, it is a Seq2seq model, premise and hypothesis are fed into encoder and decoder seperately. There are some details about using Word2vec to represent tokens.
And, for classification we use a softmax layer over the output of a non-linear projection of
the last output vector (h9 in the example) into the target space of the three classes (ENTAILMENT, NEUTRAL or CONTRADICTION), and train using the cross-entropy loss.
4. An extension of an LSTM for RTE with neural attention. The idea is to allow the model to attend over past output vectors (see Figure B), thereby mitigating the LSTM’s cell state bottleneck. In other words, when considering the latest  , we need to learn to attend to necessary
, we need to learn to attend to necessary ![[h_1, h_L]](https://image.jiqizhixin.com/uploads/editor/e89c0905-4238-4375-bb08-b8ca1117f1e5/1532260587874.png) . The formula is as follows:
. The formula is as follows:
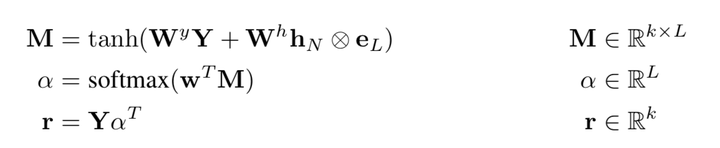
The outer product is served as a copy function. We learn weight  to get the relative importance of L hidden states. (We get r using
to get the relative importance of L hidden states. (We get r using ![[h_1, h_L]](https://image.jiqizhixin.com/uploads/editor/b77495c9-3dae-49d9-8553-a0281e647228/1532260587840.png) and
and  .
.
And finally we get the sentence-pair representation like that:
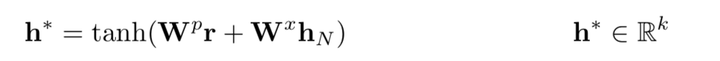
5. WORD-BY-WORD ATTENTION
It is almost same as above except that it considers  where t
where t  .
.
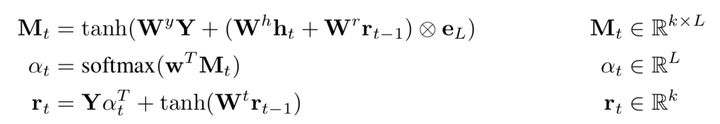
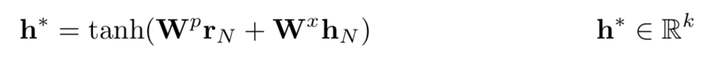
6. TWO-WAY ATTENTION
Inspired by bidirectional LSTMs that read a sequence and its reverse for improved encoding (Graves and Schmidhuber, 2005), we introduce two-way attention for RTE. The idea is to use the same model (i.e. same structure and weights) to attend over the premise conditioned on the hypothesis, as well as to attend over the hypothesis conditioned on the premise, by simply swapping the two sequences. This produces two sentence-pair representations that we concatenate for classification.
7. DISCUSSION
Conditional Encoding We found that processing the hypothesis conditioned on the premise instead of encoding each sentence independently gives an improvement of 3.3 percentage points in accuracy over Bowman et al.’s LSTM.
Attention By incorporating an attention mechanism we found a 0.9 percentage point improvement over a single LSTM with a hidden size of 159, and a 1.4 percentage point increase over a benchmark model that uses two LSTMs for conditional encoding (one for the premise and one for the hypothesis conditioned on the representation of the premise).
Word-by-Word Attention Enabling the model to attend over output vectors of the premise for every word in the hypothesis yields another 1.2 percentage point improvement compared to attending based only on the last output vector of the premise.
Two-way Attention Allowing the model to also attend over the hypothesis based on the premise does not seem to improve performance for RTE. We suspect that this is due to entailment being an asymmetric relation.
To summarize, Word-by-Word Attention is better than Attention, and Attention is better than Conditional Encoding.




