



作者:袁建华,赵怀鹏,丛大玮
一:导言
作为人工智能的重要组成部分,情感智能包括感知、理解、表达和控制情感的能力。虽然目前存在很多用来解决大规模社交网络数据的对话生成模型,但生成具有可控情感的文本仍然是一项巨大的挑战。为推动情感文本生的相关研究,NLPCC 2017组织了情感对话生成(ECG)评测(NLPCC2017 shared task 4)。在给定一句中文的微博原文X = (x1,x2, …,xn)和一种用户指定的情感emo的条件下,ECG旨在生成含有和指定情感的流畅且相关的答复Y = (y1, y2, …, yn)。例如,给定一句微博原文“我昨天丢掉了工作”,回复“我很遗憾”是合适的。
在本文中,我们提出了一套基于Seq2Seq模型生成情感回复的系统——“HIT-SCIR-Babbling”。在传统Seq2Seq模型基础上,Babbling使用微博原句的情感embedding丰富原句的表示。Babbling还融合了Learning to Start (LTS)机制,从而生成更自然的句首词。为了以提高生成词语主题的相关性,Babbling还采用attention机制,我们将传统的single hop attention 过程扩展到multi-hopattention,通过多次attention获得更为抽象并且与微博原文相关的表示,从而进一步提高生成质量。
二: seq2seq 模型
首先,简单介绍下我们用于情感对话生成的seq2seq模型。
从概率学的角度上来讲,seq2seq模型相当于在寻找在给定微博原文 X = (x1, x2, …, xn) 的情况下,寻找目标回复 Y = (y1,y2, … ym)使得p(Y|X)最大,即argmaxYp(Y|X)。在对话生成的场景中,我们使用Seq2Seq模型来最大化概率p(response | post)。在学习了条件分布后,Seq2Seq模型通过寻找在给定post的情况下使这个条件概率最大的句子来生成一个合理的回答。
典型的Seq2Seq模型由一个编码器和一个解码器组成,这两者通常用RNN及其变种(LSTM,GRU等)实现。我们的编码器和解码器都使用了一个单向两层的GRU。
在本框架中,解码器每个位置利用编码器每个隐层,形成上下文向量c。通常c的计算为
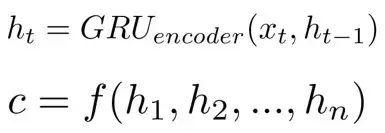
其中,ht是在t时刻的隐层状态,c是通过隐层状态计算得来的上下文向量。通常通过attention机制使用所有的隐层状态来计算c。
在解码时,通过解码部分前文表示和前一个预测的词来预测下一个词yt。这样,在t时刻解码器的隐藏状态可以表示为
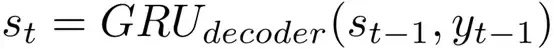
因此,在解码部分的条件概率定义为

其中,ct是在t步中用来预测当前词的上下文向量。
最后,在t时刻词可以通过匹配整个词表的可能性来计算。
仅仅通过普通的Seq2Seq模型来生成话题相关流畅的回答是一个巨大的挑战,所以我们将几种技术整合到基本的Seq2Seq模型中来改善生成内容的质量和情感一致性。我们的方法如图1所示。
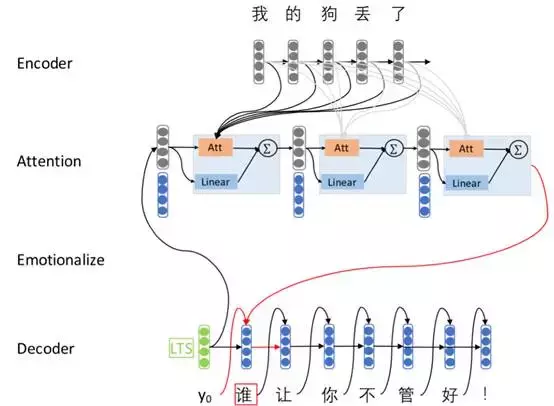
图一:我们使用multi-hop attention,LTS和情感embeddings的Seq2Seq模型图解
2.1 multi-hop attention
理想情况下,编码器能将原文序列中的所有信息都编码成一个固定长度的上下文向量c。然而,Bahdanau 等发现了固定长度的向量c :1)可能因为丢掉了在序列开始出现的词的信息而不会保留所有在原文序列中出现的有用信息;2)在解码预测时,不能建模在原文序列出现的不同词的不同贡献。为解决在基本的Seq2Seq模型中出现的这些问题,他们提出了一种attention机制,所有原文序列的隐层输出都将被使用而非最后一层隐层输出。这种方式对于解码器中每个时刻的上下文向量都是不同的,表示为

这里,解码器的第i个隐层输出的权重aij 的计算为
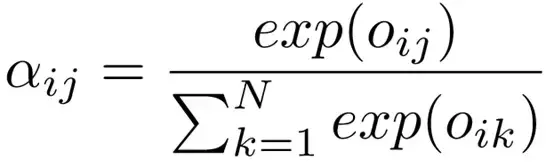

其中,a是一个非线性激励函数,如sigmod或tanh,能够被看作是在解码器中的隐层状态和编码器中隐层输出相似性测量。
多层的神经网络有着更强的表示能力。从这些工作中受到启发,我们把单层的attention拓展到多层。每层挑选出更重要的上下文词语,把前一层表示转换为更高层更抽象的表示。通过多次的attention处理可以得到一个更好的原文表示,我们希望这有助于处理语义和情感组合的问题。
2.2 LTS:learning to start
在多数Seq2Seq模型中,起始符号通常是固定的,用于解码器中生成的第一个词前的词。虽然第一个词的初始化是一个容易被人忽略的小细节,但我们认为它是Seq2Seq模型中的重要组成部分。然而,起始符号不能区分不同的原文输入,这会导致模型倾向于预测高频词。为解决这样的问题,我们在解码中使用Learning To Start (LTS)生成预测序列中的第一个词。第一个词的可能性的计算为
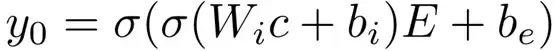
其中,c是上下文向量,这里是编码器的最后一层隐层状态,Wi是在模型中学习到的权重矩阵,bi,be是偏置向量,E是解码器的embedding矩阵,σ是非线性激励函数。
直观上,上述公式建立了解码器中上下文向量和embedding 空间之间的联系,这使原文序列和在所有预测候选词中的信息相关联。注意,第一个词的生成仅取决于编码器的状态,这和原句子不同,也消除了起始符号的影响,共同减少了编码器的信息损失。
2.3 emotion embeddings
为使模型能生成用户指定情感类别的回复,我们引入情感类别embeddings。我们在attention过程中加入情感类别信息,它直接指导上下文信息的选择和生成回复的情感倾向变化。我们随机初始化情感embedding,与模型的其他部分共同参与训练。解码器中的条件概率计算方式如下:

其中,et是用户指定类别的情感embedding.
三 实验
3.1 数据集
我们训练模型使用的大规模数据集来自微博,包含1119207对(post, response)。数据集的统计如表1所示。我们使用Bi-LSTM给出的微博和原文的情感标签,并且可视化情感转移信息的分布情况,如图2所示。
表1:数据集的统计信息

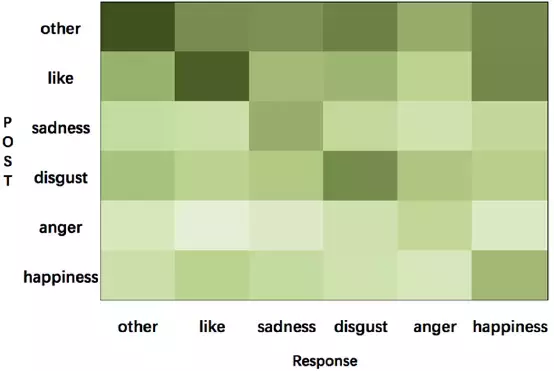
图2:微博训练数据上从post到response的情感转移可视化,颜色深度代表着每种类型转换的比例
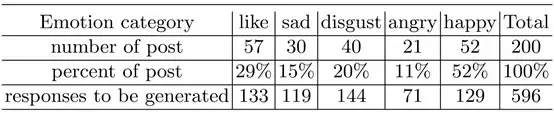
由于目前还没有评估生成结果的标准方法,所以NLPCC 2017 Shared Task 4采用人工评估。如果回复的内容是流畅、合适的得一分,如果回复文本的情感和用户指定的情感类别一致,则再加一分。因为人工评估所有的提交结果很费时费力,所以选择200个微博原文作为最终评估集。人工评价部分的数据集统计数据如表2所示。
表2:最终评测集的统计数据
3.2 模型实现
我们编码器和解码器均使用隐层维度为200的双层GRU。编码器和解码器使用不同的词表,其中在post、response中词频不超过5的词将会被删除,使用UNK代替这些不常见的词,并在post和response中添加结束符号。我们设定word embedding和emotion size大小为100。根据对post和response句子长度的分析,我们设置post和response的长度为10,batch设为64,通过采样正态分布(-0.1,0.1)初始化参数。我们使用sampled softmax 加速预测过程。我们的模型使用Tensorflow 0.12实现。
3.3 结果
在这一部分,我们根据生成结果对我们的模型进行定性分析。
LTS的有效性。我们比较了基本的Seq2Seq模型和使用LTS扩展的模型。表3中的例子显示,使用LTS可以产生更好的第一个词,更流利和话题相关的回答。LTS能够改善第一个词和整个句子的质量。
表3:基本Seq2Seq模型和LTS扩展生成结果的对比

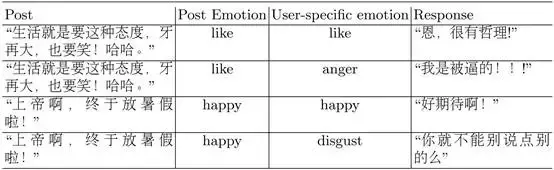
使用情感embedding带来的情感转变。图2展示了训练数据情感转移的分布(emotion transition)。我们可以看到回答通常使用和post相同的情感标签。例如,带有“like”标签的post少见有带有”anger”标签的回答,反之亦然。一部分从“like”到“happiness”的转换和从“happiness”到“like”的转换是相似的,这表现了两种情感是相接近的,也意味着对于情感分类器来说区分“like”和“happiness”是有一定难度的。换句话说,情感分类器的效果对情感回答生成有着很大的影响。在attention过程使用情感embedding后,Seq2Seq模型能够生成用户指定情感,如表4所示。在我们的模型中,attention过程中的情感embedding在情感对话生成中是至关重要的。
表4:带有情感embedding的Seq2Seq模型生成的用户指定情感的回答例句
四: 总结
在这项工作中,我们提出了基于神经网络的情感回复系统HIT-SCIR-Babbling,我们在Seq2Seq结构中使用了LTS,MTA和情感embedding,并通过生成例句解释了这些方法的有效性。
本期责任编辑: 刘一佳
本期编辑: 赵怀鹏



