




授权转载自:数据派THUID:DatapiTHU
数据科学中,数据的爬取和收集是非常重要的一个部分。本文将以众筹网站FundRazr为例,手把手教你如何从零开始,使用Python中非常简便易学的Scrapy库来爬取网络数据。
用Python进行网页爬取
当我开始工作时,我很快意识到有时你必须收集、组织和清理数据。 本教程中,我们将收集一个名为FundRazr(https://fundrazr.com/)的众筹网站的数据。像许多网站一样,该网站具有自己的结构、形式,并具有大量可访问的有用数据,但由于没有结构化的API,很难从站点获取数据。 因此,我们将爬取这个网站,获得非结构化的网站数据,并以有序的形式建立我们自己的数据集。
为了爬取网站,我们将使用Scrapy(https://scrapy.org/)。简而言之,Scrapy是一个框架,可以更轻松地构建网络爬虫并降低护它们的难度。基本上,它可以让您更专注于使用CSS选择器进行数据提取,选取XPath表达式,而不必了解爬虫工作的具体细节。这篇博客文章略微超出Scrapy文档中官方教程(https://doc.scrapy.org/en/latest/intro/tutorial.html)的教学范畴,如果您需要更多地爬取某些东西,可以看着这篇文章自己做。 现在,让我们开始吧。如果您感到迷惑,可以在新标签页打开这个视频(https://www.youtube.com/watch?v=O_j3OTXw2_E)。
入门(先决条件)
如果您已经拥有anaconda和谷歌Chrome(或Firefox),请跳到创建新的Scrapy项目。
1. 在您的操作系统上安装Anaconda(Python)。 您可以从官方网站下载anaconda,还可以自行安装,或者您可以按照下面的这些anaconda安装教程进行安装。
Operating System | Blog Post | Youtube Video |
Mac | Install Anaconda on Mac | Youtube Video |
Windows | Install Anaconda on Windows | Youtube Video |
Ubuntu | Install Anaconda on Ubuntu | Youtube Video |
All | Environment Management with Conda (Python 2 + 3, Configuring Jupyter Notebooks) | Youtube Video |
安装Anaconda
2.安装Scrapy(anaconda附带Scrapy,但以防万一)。 您还可以在终端(mac / linux)或命令行(windows)上安装。 您可以键入以下内容:
conda install -c conda-forge scrapy
3.确保您有Google Chrome或Firefox。 在本教程中,我使用的是Google Chrome。 如果您没有Google Chrome,可以使用此链接安装(https://support.google.com/chrome/answer/95346?co=GENIE.Platform%3DDesktop&hl=en)
创建一个新的爬取项目
打开终端(mac / linux)或命令行(windows)。 进入所需的文件夹(如果需要帮助,请参阅下图)并键入
scrapy startproject fundrazr

scrape起始项目fundrazr
这就会生成一个含有如下内容的fundrazr目录:
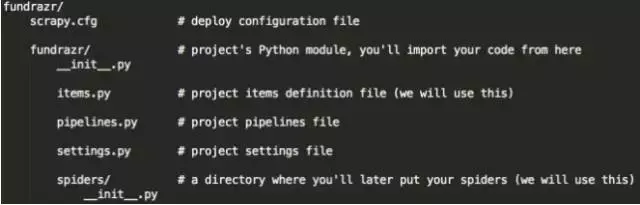
fundrazr项目目录
使用Google Chrome浏览器(或Firefox)查找好起始URL
在爬虫框架中,start_urls是当没有指定特定网址时爬虫开始抓取的网址列表。我们将使用start_urls列表中的元素来获取单个筹款活动链接。
1.下面的图片显示,根据您选择的类别,您将获得不同的起始网址。 黑色突出显示的部分是我们此次爬取的分类。
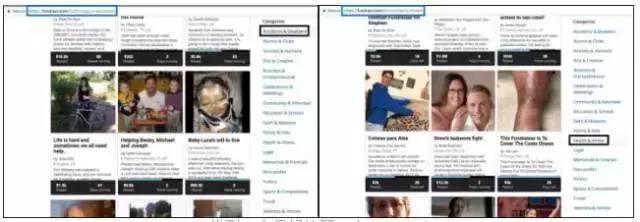
找到一个很好的第一个start_url
对于本教程,列表start_urls中的第一个是:https://fundrazr.com/find?category=Health
2.这部分是关于获取更多的元素来放入start_urls列表。 我们需要找出如何去下一页,以便可以获得额外的url来放入start_urls。
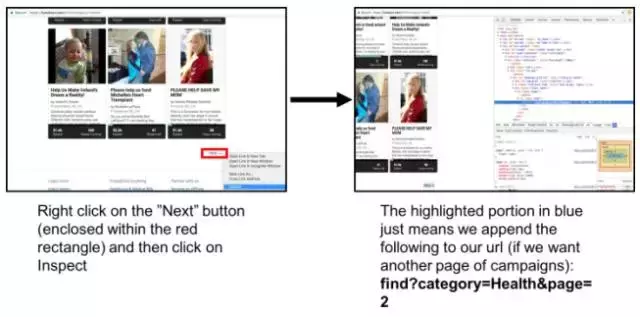
第一幅图:在“Next”上点击鼠标右键(红色方框内)然后点击“Inspect”
第二幅图:蓝色高亮部分表示我们在我们的url后面加上了(如果我们想要另一页筹款活动:find?category=Health&page=2
(通过检查“下一步”按钮获取其他元素以放入start_urls列表)
第二个起始URL:https://fundrazr.com/find?category=Health&page=2
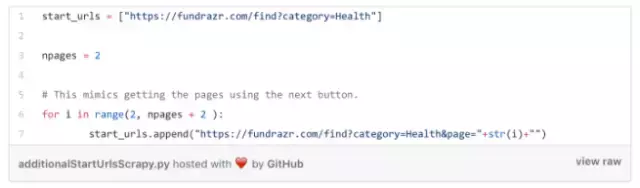
下面的代码将在本教程后面的代码中用于爬虫。 它的作用是创建一个start_urls列表。变量npages代表的是我们想从多少个额外的页面(在第一页之后)中获取筹款活动链接。
(根据网站的现有结构生成额外的起始URL代码)
查找单个筹款活动链接的Scrapy Shell
学习如何使用Scrapy提取数据的最佳方法是使用Scrapy shell。我们将使用可用于从HTML文档中选择元素的XPath。
我们所要做的第一件事是尝试获得提取单个筹款活动链接的xpath表达式。 首先,我们查看筹款活动的链接大致分布在HTML的哪个位置。
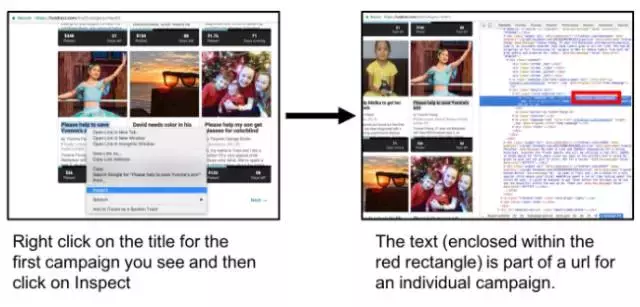
第一幅图:右键点击你看到的第一个筹款活动链接,然后点击“inspect”
第二幅图:这个文本(红色方框内)是单个活动筹款URL 一部分
(查找到单个筹款活动系列的链接)
我们将使用XPath来提取包含在下面的红色矩形中的部分。

被框住的部分是我们将单独拎出来的部分网址
在终端(mac / linux)中输入:
scrapy shell ‘https://fundrazr.com/find?category=Health'
命令行输入(windows):
scrapy shell “https://fundrazr.com/find?category=Health”
输入以下内容到scrapy shell(以帮助了解代码,请参见视频):
response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href").extract()
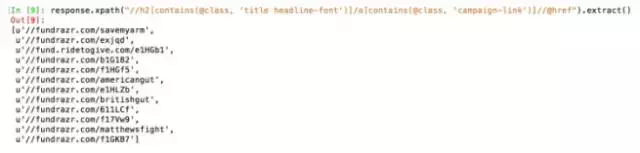
随着时间的推移,随着网站的更新,您有可能会获得不同的URL
下面的代码是为了获取给定的初始URL所包含的所有活动链接(在First Spider部分会更详细地说明)
for href in response.xpath("//h2[contains(@class, 'title headline-font')]/a[contains(@class, 'campaign-link')]//@href"):
# add the scheme, eg http://
url = "https:" + href.extract()
通过输入exit()退出Scrapy Shell。

退出scrapy shell
检查单个筹款活动
我们已经了解了单个筹款活动链接的结构,本节将介绍各个筹款活动页面的内容。
1.接下来,我们打开一个单独的筹款活动页面(见下面的链接),以便爬取(我提醒一下,有些活动很难查看):https://fundrazr.com/savemyarm
2.使用与以前相同的检查过程,我们检查页面上的标题
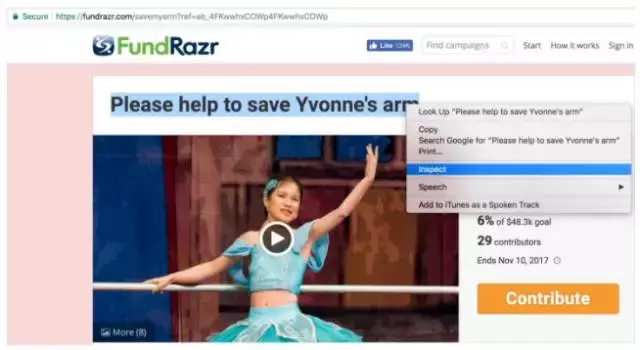
检查筹款活动标题
3.现在我们要再次使用scrapy shell,但这次是通过一个单独的筹款活动。 我们这样做是因为我们想要了解各个筹款活动页面的格式(包括了解如何从网页中提取标题)
在终端输入 (mac/linux):
scrappy shell 'https://fundrazr.com/savemyarm'
在命令行输入 (windows):
scrapy shell “https://fundrazr.com/savemyarm"
获取筹款活动标题的代码是:
response.xpath("//div[contains(@id, ‘campaign-title')]/descendant::text()").extract()[0]

4.我们可以对页面的其他部分做同样的事情。
筹集的额度:
response.xpath("//span[contains(@class,'stat')]/span[contains(@class, 'amount-raised')]/descendant::text()").extract()
目标:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]//span[contains(@class, 'stats-label hidden-phone')]/text()").extract()
货币的类型:
response.xpath("//div[contains(@class, 'stats-primary with-goal')]/@title").extract()
筹款活动结束日期:
response.xpath("//div[contains(@id, 'campaign-stats')]//span[contains(@class,'stats-label hidden-phone')]/span[@class='nowrap']/text()").extract()
贡献者数量:
response.xpath("//div[contains(@class, 'stats-secondary with-goal')]//span[contains(@class, 'donation-count stat')]/text()").extract()
故事:
response.xpath("//div[contains(@id, 'full-story')]/descendant::text()").extract()
网址:
response.xpath(“//meta[@property='og:url']/@content").extract()
5. 退出scrapy shell:
exit()
ITEMS
爬取的主要目标是从非结构化数据源(通常是网页)中提取结构化数据。 Scrapy爬虫可以将提取的数据以Python dicts的形式返回。虽然非常方便,操作也很熟悉,但是Python dicts本身缺少结构化:容易造成字段名称中的输入错误或返回不一致的数据,特别是在具有许多爬虫的较大项目中(这一段几乎是直接从scrapy官方文档复制过来的)。
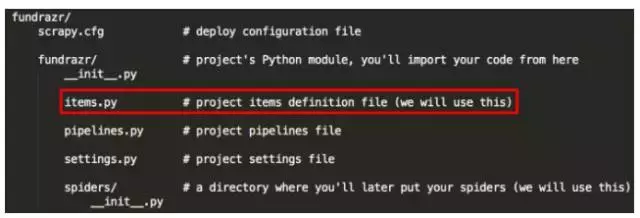
我们将修改的文件
items.py的代码在这里:
https://github.com/mGalarnyk/Python_Tutorials/raw/master/Scrapy/fundrazr/fundrazr/items.py
保存在fundrazr / fundrazr目录下(覆盖原始的items.py文件)。
本教程中使用的item类 (基本上是关于在输出以前,我们如何存储我们的数据的)看起来像这样。
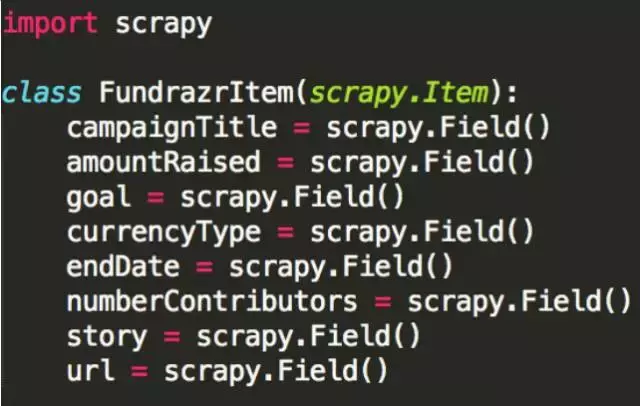
items.py的代码
爬虫
爬虫是您所定义的类,Scrapy使用它来从一个网站或者一组网站爬取信息。我们的爬虫代码如下:
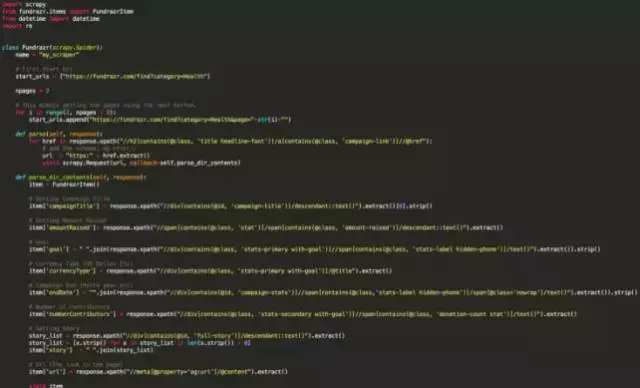
Fundrazr Scrapy的代码
在这里下载代码:https://raw.githubusercontent.com/mGalarnyk/Python_Tutorials/master/Scrapy/fundrazr/fundrazr/spiders/fundrazr_scrape.py
将它保存在fundrazr / spiders目录下,名为fundrazr_scrape.py的文件中。
目前项目应具有以下内容:
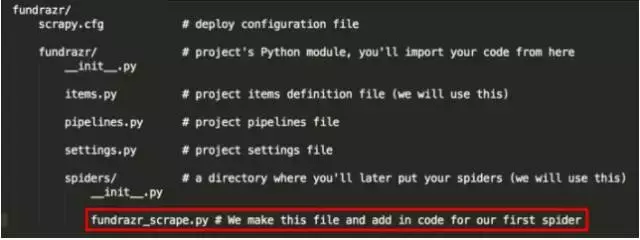
我们将创建/添加的文件
运行爬虫
1.前往fundrazr / fundrazr目录,并输入:
scrapy crawl my_scraper -o MonthDay_Year.csv

scrapy crawl my_scraper -o MonthDay_Year.csv
2. 数据应该输出到fundrazr/fundrazr目录。
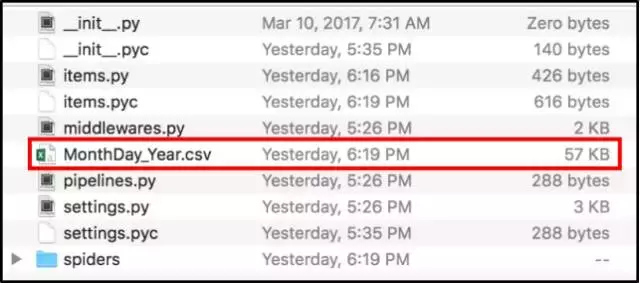
我们的数据
本教程中输出的数据大致如下图所示。 随着网站不断更新,爬取出来的个别筹款活动将会有所不同。 此外,在excel读取csv文件的过程中,不同的活动数据间可能会出现空格。
数据应该大致为这种格式
2.如果要下载较大的文件(这个是通过将npages = 2更改为npages = 450并添加download_delay = 2来爬取得),您可以从我的github(https://github.com/mGalarnyk/Python_Tutorials/tree/master/Scrapy/fundrazr/fundrazr)上下载包含大约6000个筹款活动的文件。 该文件称为MiniMorningScrape.csv(这是一个大文件)。
大约6000个筹款活动被爬取
结束语
创建数据集需要大量的工作,而且往往是数据科学学习被忽略的一部分。还有一件没有解决的事情是,虽然我们已经爬取了大量的数据,我们还没有对数据进行足够的清洗,所以还不能做分析。不过那是另一个博客帖子的内容了。如果您有任何问题,可以在这里或者是Youtube页面(https://www.youtube.com/watch?v=O_j3OTXw2_E)留言告诉我!
原文链接:
https://medium.com/towards-data-science/using-scrapy-to-build-your-own-dataset-64ea2d7d4673
