



这次的故事,要从并行计算机体系结构讲起。说到并行计算机体系结构,就要掉一个书袋——

小编置入行销不买不吃亏之一
我从上的第一门计算机体系结构课,到并行提算计体系机构,到高级计算机体系结构都在用这一本书。不得不感谢作者让我少买了好多教科书钱。当然,牛x书的作者也很牛x,这里就不八卦了。有人愿意把这本📖叫做计算机体系结构的bible,我不评论,但是下面我们所讲的,好多都出自这本书。
言归正传,这个特立独行的故事从这里开先,我们要认识一个老爷爷(还活着好像),他叫Michael Flynn。老人家生于大萧条时代的扭腰城,一不小心提出了一个分类法,叫做Flynn Taxonomy(1966)。然后计算机体系机构就被Flynn taxonomy的五指山给压几十年。

Flynn Taxonomy的五指山把计算机结构分为两个部分:指令与数据,在时间轴上指令与数据可以单步执行或多次运行进行分类,即单指令单数据(SISD),单指令多数据(SIMD),多指令单数据(MISD)和多指令多数据(MIMD)。
Flynn taxonomy给并行计算机体系结构指了两条明路——指令级并行和数据级并行。
首先来看下指令与数据的关系。指令是处理器单步可以实现的操作的集合。指令集里的每一条指令,都包含两个部分(1)什么操作,(2)对什么数据进行操作。专业地,我们把前者叫做opcode,后者叫做operand(也就是数据)。当然,并不是所有的命令都有数据操作。传统定义的指令集里面,对应的operand不超过2。比如,加减乘除都是典型的二元操作。数据读写就是一元的,还有些就是没有任何数据的操作,比如一个条件判断(if)发生了,根据判断结果程序何去何从,只是一个jump操作,他并不需要任何数据输入。

你还记得脑芯编(一)
提到的一个neuron计算么?
每一个neuron都要经历n个输入的乘累加~
指令级并行的第一种、也是最经典的办法叫做时间上并行,这是所有的体系结构教科书最喜欢教的流水线架构(pipeline)。简而言之,在发明流水线以前,处理器里面只有一个老司机,什么事情都得他来干,但是下一条指令得等老司机干完上一个~但是,流水线就是把一个老死机变成了三个臭皮匠,每个人干三分之一就给下一个,这样下一条指令只需在上一条被干完1/3后就可以进来了。虽然老司机体力好,但赶不上年轻的臭皮匠干的快啊。这样,流水线可以实现时间上的指令集并行,成倍提高实际指令的处理效率。
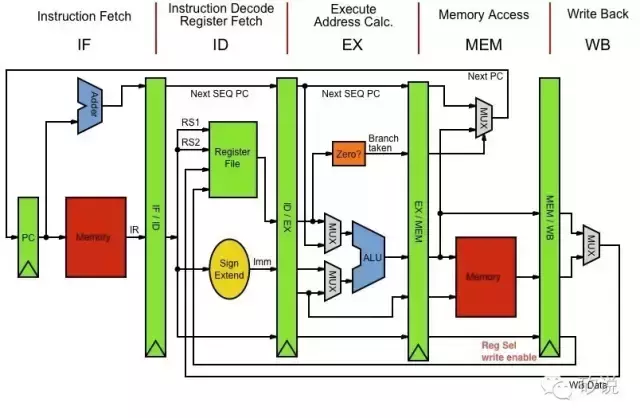
经典MIPS-5 级流水线
有一就有二,有时间当然就有空间。所以,第二种办法是空间上的并行。空间并行基于一个观察——对数据的操作有很多种——加减乘除移位、整数操作、浮点操作……每一个模块的处理(ALU/EXU)是独立的,所以,就空间上,一个浮点加法在处理的时候,完全可以同时进行一个整数移位操作,像老顽童教小龙女的左右互搏分心二用。所以,在计算机体系的历史上,练成“左右互博”术的处理器包括超标量(Superscalar)/超长指令(Very Long Instruction Word, VLIW)处理器。具体我们先不展开。
相比于流水线/超标量复杂的修炼过程(黄蓉都练不会“左右互博”),数据级并行就是简单纯粹的叠加硬件,打造并行处理的“千手观音”:

“千手观音”的学名叫做SIMD,Single Instruction Multiple Data,单指令多数据(流)处理器。其实,说白了就是原来有处理单元(ALU/EXU)现在一个加法器,现在变成了N个了。对应神经网络的计算,原来要M次展开的乘累加,现在只要M/N次,对应的时钟和时间都显著地降低。 
简单粗暴的并行,不仅提高了让每个指令的数据吞吐率,还让本身单一的标量处理进化成阵列式的“矢量型”处理,于是就有SIMD又有了“矢量处理”指令的称呼。其实,SIMD并不是到了神经网络再兴起的新玩样儿,早在MP3的年代,SIMD处理器就广泛地使用在各类信号处理芯片中。所以关于SIMD指令也早有了需要行业标准。以下,我们就来看一个SIMD指令集实例——
在上一编中,我们简单提到了史上第一个攻城掠地的RISC-ARM。为手机、平板等便携式的最重要处理器,ARM的SIMD指令也是王者风范,从它的名字开始——NEON。
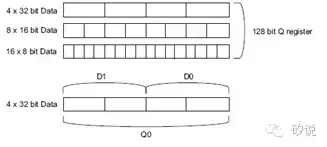
NEON的指令的操作的输入(operand)是一组128位位宽的寄存器,但这个寄存器存着的几个数,就由码农自己去预定义了,可以是4个32位的浮点,或者定点,或者8个16位定点,或者16个8位定点……整个指令集宽泛地定义了输入、输出的位宽,供变成者自由支配,考虑到在神经网络中,前馈网络往往只要16位、8位整数位宽,所以最高效的NEON命令可以一次实现16个乘累加计算(16个Synapse)。
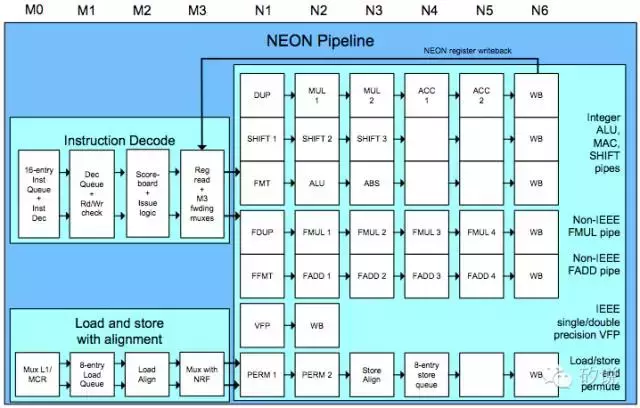
仅仅是SIMD怎能彰显NEON的侠者风范? NEON还充分应用了指令级并行,采用10级流水线(4级decode+6级运算单元),可以简单地理解为把卷积计算的吞吐率由提高了10倍。加起来,相比与传统的单指令5级流水,提高至少32倍的效率。再辅以ARM Cortex A7以上的超标量核心处理单元,筑起了第一条通用并行计算的快车道。
流水线和SIMD都是在神经网络还没羽翼丰满的时候就已经称霸江湖的大侠。在神经网络不可一世的今天,这两者还是固步自封么?答案显然是否定的。
当通用SIMD处理器遇上神经网络,他们既碰撞出了火花,也开始相互埋怨。我们先说埋怨——存储空间管理。我们知道,在NN中通常每个卷积核都需要先load系数与输入数据,再算出部分的乘累加结果,再store回存储空间。而指令执行与存储空间的通信就是我们上一编讲到的——冯诺伊曼瓶颈。对于神经网络来说,如此多次的存储读写是制约性能的关键。减少数据的载入与中间结果是面向神经网络的SIMD指令的主要问题。
那火花是什么?
在深度神经网络,特别CNN中
每个卷积核——
相邻状态的数据输入
只更新了小部分,
而大部分数据保持不变
但更换了对应系数
这就给SIMD带来了一个面向神经网络的新机遇——部分更新与数据滑行(sliding)。我们来看下面这张动图「原作为MIT Eyeriss项目研究组」。

对于一个采用SIMD的卷积核,有一组输入是固定——系数矢量,而另一组输入像一个FIFO,在起始填满后,每次注入一个单元(也排出一个单元)进行乘雷佳,另外上一次累加的结果在保存在执行单元的寄存器内,只有最终的卷积核结果会写回到存储器中。
这样,在神经网络中,无论是数据导入、还是结果输出,起对存储空间的访问都会大大降低。当然,上述示意图仅仅是一维的。当卷积核的维度达到二三维时,情况会复杂很多。这里推荐大家可以去读读MIT的Eyeriss,Kaist的MIMD,或者IMEC的2D-SIMD(ENVISION)。这里就不太多展开了。
好了,这次就到这里。所谓“烛台簇华照单影”就是那一粒粒自由定义的小数据,在同一声SIMD的指令下,排成队,集成行,成为了一个孤独的矢量运算。
