从去年七月起,Google就号称了其面向深度学习的专用集成电路(ASIC)产品——Tensor Processing Unit (TPU),然而其神秘面纱一直未被揭开。直至本周,Google公开了其向ISCA(国际计算机体系架构年会)投稿的的预录取论文——In Datacenter Performance Analysis of a Tensor Processing Unit,TPU的技术细节才公开发表,令我们才有幸见识其真面目。虽然可能只是“犹抱琵琶半遮面”,但其作为CPU/GPU/FPGA后的另一深度学习选项,特别是TPU和tensorflow间可能存在的微妙联系值得我们特别关注。矽说在第一时间选编、翻译了其中的重要部分,以飨读者。

论文地址:(需翻墙) https://drive.google.com/file/d/0Bx4hafXDDq2EMzRNcy1vSUxtcEk/view
前言
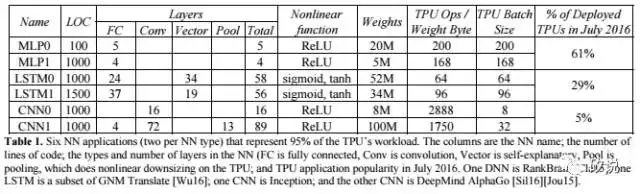
文章具体描述了Tensor Processing Unit (TPU)的体系结构,并与目前主流的CPU(Intel Haswell Xeon)和GPU(Nvidia K80)的性能做出了比较,采用的benchmark包含了CNN,RNN(LSTM)和全链接(MLP)神经网络。其特点包括:
(1) 面向inference的专用app与硬件,强调了吞吐率上的性能
(2) TPU的不仅在面积和功耗上低于GPU,而且在乘累加的数量和存储器容量是K80的25倍和3.5倍
(3) TPU的速度上的优势明显,达到GPU和CPU的15到30倍
(4) 在6个NN架构中,4种神经网络的性能瓶颈在于存储器带宽。若存储器带宽达到K80的性能,作者相信性能能提升到30到50倍
(5) TPU的能效值(TOPS/W)达到在目前其他产品的30到80倍
(6) CNN在TPU中工作量的比列只有5%
起源、架构与实现
早在2006年开始,Google就开始讨论在数据中心部署GPU,FPGA或定制ASIC。在2013年,当DNN已经展露头脚,以致可能会使我们的数据中心的计算需求加倍时,传统的CPU已经被认为不合时宜了。因此,我们开始了一个高度优先的项目,以快速生成用于Inference的定制ASIC,(训练仍使用GPU)。 目标是将性能提升10倍以上。 根据这一任务,Google的TPU的设计和验证在短短15个月内完成,并构建并部署在数据中心。
而不是与CPU紧密集成,为了减少延迟部署的可能性,TPU被设计为PCIe I/O总线上的协处理器,允许它像GPU那样插入现有的服务器。 此外,为了简化硬件设计和调试,主机服务器发送TPU指令来执行,而不是自己提取它们。 因此,TPU在精神上比FPU(浮点单元)协处理器更接近于GPU。
TPU的目标是运行整体深度学习的神经网络模型,以减少与主机CPU的交互,并且具有足够的灵活性,以满足2015年及其后的NN需求,而不仅仅是2013年NN所需。

图1是TPU的整体体系架构。TPU指令通过PCIe Gen3 x16总线从主机发送到指令缓冲区。 内部块通常通过256字节宽的路径连接在一起。 从右上角开始,Matrix Multiply Unit是TPU的核心。 它包含256x256个乘累加单元(MAC),可以对有符号或无符号整数执行8位乘法和加法。 求和单元(Accumulator)的输入为16位乘积,输出和的位宽为32,共有4906个,每个的输入个数为256。 因此,矩阵单元每个时钟周期产生一个256元素的部分和。
当使用8位权重和16位激活函数的混合计算结构时,MMU的计算速度将减半,当它们都是16位,计算速度将减为四分之一。 它每个时钟周期读取和写入256个值,并且可以执行矩阵乘法或卷积。 矩阵单元采用两个64KiB的权重tile的双缓冲设计,其中的一个仅在非稀疏模式下才会被激活,这样就提升了TPU对于稀疏网络的性能支持。Google相信稀疏性将在未来的设计中占有优先地位。
矩阵单元的权重通过片上Weight FIFO进行分级,该FIFO从片外8 GiB DRAM读取(在inference中,权重是只读的)。Weight FIFO存储了四个4个tile。 中间结果保存在24 MiB片上Unified Buffer中,可作为未来的Matrix单元的输入。 可编程DMA控制器向CPU主机内存和Unified Buffer传输数据。

图2显示了TPU芯片的布局图。 24 MiB Unified Buffer几乎是芯片的三分之一,Matrix Multiply Unit是四分之一,因此数据路径占到了整个芯片的三分之二。由于开发时间短,部分设计选取了简单的值以简化编译器设计。 控制逻辑占到总面积的只有2%。 图3显示了搭载在PCB上的TPU实现图,期接口类似SATA磁盘,可通过PCIe直接接入数据中心。

TPU的指令是通过PCI额发射的,遵循CISC传统,包括重复字段。 这些CISC指令的每个指令的平均时钟周期(CPI)在10到20之间。它总共有大约十多个指令,这里罗列最关键的五个:
(1) Read_Host_Memory
(2) Read_Weights
(3) MatrixMultiply/Convolve
(6) Activation
(5) Write_Host_Memory
其他指令是备用主机内存读/写,设置配置,两个版本的同步,中断主机,调试Jtag,空操作和停止。 CISC MatrixMultiply指令为12个字节,其中3个为Unified Buffer地址; 2是累加器地址; 4是长度(有时是卷积的2个维度); 其余的是操作码和标志。TPU微架构的理念是保持MMU的繁忙。 因此,MMC的CISC指令使用4级流水线结构,其中每条指令在其中的单独一级执行。 其目标是通过将其执行与MatrixMultiply指令重叠来隐藏其他指令(如Read_Weights等)。但,当激活的输入或权重数据尚未就绪,矩阵单元将进入等待模式。
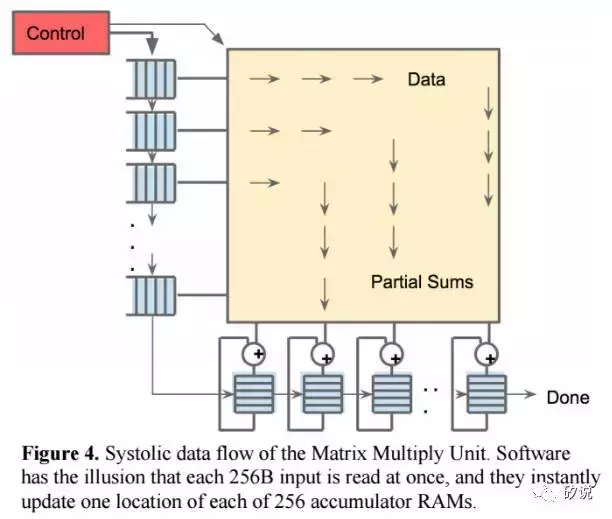
由于读取大型SRAM数据的功耗比算术功耗高的多,所以MMU通过systolic方式减少对Unified Buffer的方位,节省功耗。 图4显示了TPU数据流程,输入从左侧流入,权重从顶部加载。 给定的256元乘法累加运算通过矩阵作为对角波前移动。 此过程中权重是预先加载的,并且与数据同步。通过对控制逻辑和数据流水线操作,使得对于MMU而言,256个输入一次读取的,并且它们立即更新到256个累加器中的一个个具体位置。 从正确的角度来看,软件不知道硬件的systoli特性,但是却需要对于systoilc引起的延时效果有正确的评估。
TPU软件堆栈必须与为CPU和GPU开发的软件栈兼容,以便应用程序可以快速移植到TPU。在TPU上运行的应用程序的一部分通常写在TensorFlow中,并被编译成可以在GPU或TPU上运行的API。像GPU一样,TPU堆栈分为用户空间驱动程序和内核驱动程序。内核驱动程序是轻量级的且长期稳定的,只处理内存管理和中断。用户空间驱动程序频繁更改。它设置和控制TPU执行,将数据重新格式化为TPU命令,将API调用转换为TPU指令,并将其转换为应用程序二进制文件。用户空间驱动程序在首次评估模型时编译模型,缓存程序映像并将重量映像写入TPU的重量存储器; 第二次和以下评估全速运行。 对于大部分模型,TPU可以从输入到输出完整实现。实际操作中,同一时间通常每次进行一层的MMC计算,而其非关键路径操作将被隐藏在MMU操作下。
CPU、GPU与TPU的性能比较
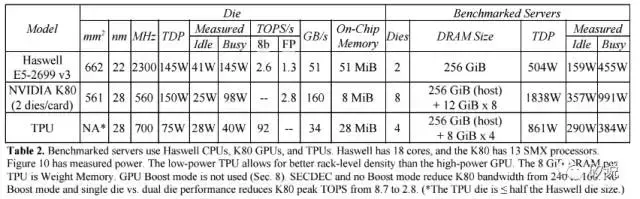
在TPU与CPU和GPU的性能比较部分,Google选择了两款并非最新但具有代表性的平台——Intel Haswell架构的Xeon 5处理器和Nvidia的K80处理器,其集成板卡后的性能对比如下:
以MLP0为例子,7ms的反应时间内TPU可得到的数据处理吞吐率是CPU和GPU的数十倍(但值得指出的是,该benchmark下TPU的计算占用率要远远高于GPU和CPU)。
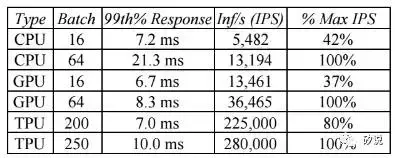
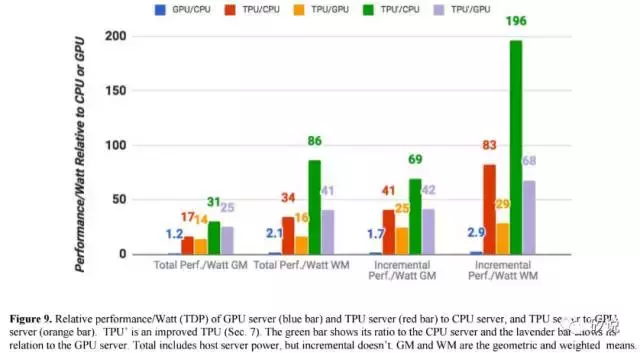
图9将K80 GPU和TPU相对于Haswell CPU的几何平均功耗性能进行了对比,包括两种计算量程——第一个是“总计”性能/瓦,包括在计算GPU和TPU的性能/瓦特时由主机CPU服务器消耗的功率。;第二个“增量”性能/瓦,仅包括预先从GPU和TPU中减去主机CPU服务器的电源余下的功耗。TPU服务器的总性能/瓦特比Haswell高出17到34倍,这使得TPU服务器的性能/ Katt服务器的功率是14到16倍。 TPU的相对增量性能/瓦特(Google致力于定制ASIC的核心价值)为41到83,这将TPU提升到GPU的性能/瓦特的25到29倍。