



作者丨刘大一恒
学校丨四川大学博士生

本期我们将介绍 KB-QA 传统方法之一的信息抽取(Information Extraction),我们以一个该方法的经典代表作为例,为大家进一步揭开知识库问答的面纱。该方法来自约翰·霍普金斯大学 Yao X, Van Durme B. 的 Information Extraction over Structured Data: Question Answering with Freebase(文章发表于 2014 年的 ACL 会议)。
该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案。通过观察问题,依据某些规则或模板进行信息抽取,得到表征问题和候选答案特征的特征向量,建立分类器,通过输入特征向量对候选答案进行筛选,从而得出最终答案。
1. 你是如何回答问题的
想一想,如果有人问你 “what is the name of Justin Bieber brother?" ,并且给你一个知识库,你会怎么去找答案?显然,这个问题的主题(Topic)词就是 Justin Bieber,因此我们会去知识库搜索 Justin Bieber 这个实体,寻找与该实体相关的知识(此时相当于我们确定了答案的范围,得到了一些候选答案)。
接下来,我们去寻找和实体关系 brother 相关的实体(事实上 freebase 里没有 brother 这个实体关系,而是 sibling,我们需要进行一个简单的推理),最后得到答案。
而信息抽取的方法,其灵感就是来自于刚才我们的这种思考方式。
2. 如何对问题进行信息抽取
还是这个例子,让我们先放慢脚步,想想我们人类是怎么对这个问题进行信息抽取和推理的。首先,我们会潜意识地对这个句子结构进行分析,下图是 “what is the name of Justin Bieber brother?" 这个问句的语法依存树(Dependency tree),如果你对依存树不了解,可以把它理解成是一种句子成分的形式化描述方式。
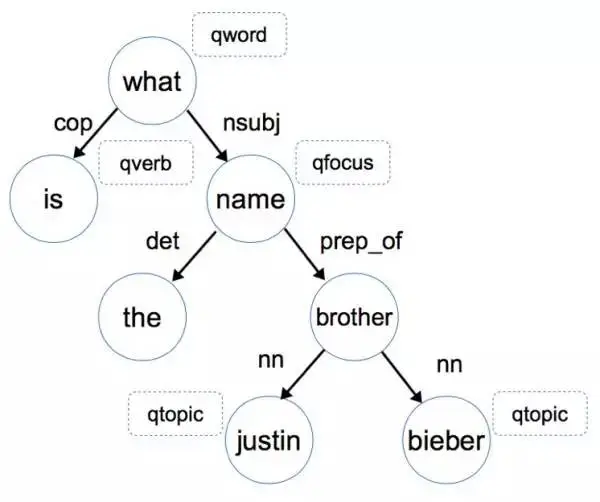
我们首先通过依存关系 nsubj (what, name) 和 prep_of (name, brother) 这两条信息知道答案是一个名字,而且这个名字和 brother 有关,当然我们此时还不能判断是否是人名。
进一步,通过 nn (brother, justin bieber) 这条信息我们可以根据 justin bieber 是个人,推导出他的 brother 也是个人,综合前面的信息,我们最终推理出来我们的答案应该是个人名。(注:这里 nsubj 代表名词性主语,prep_of 代表 of 介词修饰,nn 代表名词组合)当确定了最终答案是一个人名,那么我们就很容易在备选答案中筛选出正确答案了。
我们刚才进行的步骤,实际上就是在对问题进行信息抽取,接下来,让我们看看这篇文章具体是怎么实施的。
首先我们要提取的第一个信息就是问题词(question word,记作 qword),例如 who, when, what, where, how, which, why, whom, whose,它是问题的一个明显特征 。
第二个关键的信息,就是问题焦点(question fucus,记作 qfocus),这个词暗示了答案的类型,比如 name/time/place,我们直接将问题词 qword 相关的那个名词抽取出来作为 qfocus,在这个例子中,what name 中的 name 就是 qfocus。
第三个我们需要的信息,就是这个问题的主题词(word topic,记作 qtopic),在这个句子里 Justin Bieber 就是 qtopic,这个词能够帮助我们找到 freebase 中相关的知识,我们可以通过命名实体识别(Named Entity Recognition,NER)来确定主题词,需要注意的是,一个问题中可能存在多个主题词。
最后,第四个我们需要提取的特征,就是问题的中心动词(question verb ,记作 qverb),动词能够给我们提供很多和答案相关的信息,比如 play,那么答案有可能是某种球类或者乐器。我们可以通过词性标注(Part-of-Speech,POS)确定 qverb。
通过对问题提取问题词 qword,问题焦点 qfocus,问题主题词 qtopic 和问题中心动词 qverb这四个问题特征,我们可以将该问题的依存树转化为问题图(Question Graph),如下图所示:
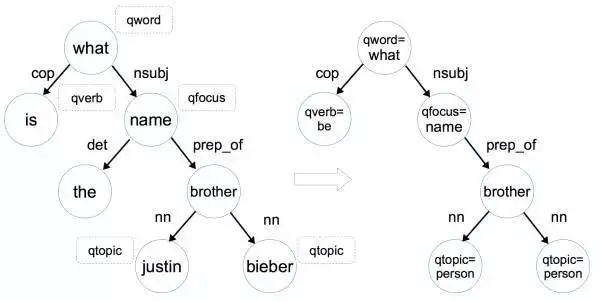
具体来说,将依存树转化为问题图进行了三个操作:
1)将问题词 qword,问题焦点 qfocus,问题主题词 qtopic 和问题中心动词 qverb 加入相对应的节点中,如 what -> qword=what。
2)如果该节点是命名实体,那就把该节点变为命名实体形式,如 justin -> qtopic=person (justin 对应的命名实体形式是 person)。这一步的目的是因为数据中涉及到的命名实体名字太多了,这里我们只需要区分它是人名 地名 还是其他类型的名字即可。
3)删除掉一些不重要的叶子节点,如限定词(determiner,如 a/the/some/this/each 等),介词(preposition)和标点符号(punctuation)。
从依存树到问题图的转换,实质是就是对问题进行信息抽取,提取出有利于寻找答案的问题特征,删减掉不重要的信息。
3. 如何构建特征向量对候选答案进行分类
在候选答案中找出正确答案,实际上是一个二分类问题(判断每个候选答案是否是正确答案),我们使用训练数据问题-答案对,训练一个分类器来找到正确答案。那么分类器的输入特征向量怎么构造和定义呢?
特征向量中的每一维,对应一个问题-候选答案特征。每一个问题-候选答案特征由问题特征中的一个特征,和候选答案特征的一个特征,组合(combine)而成。
问题特征:我们从问题图中的每一条边 e(s,t),抽取 4 种问题特征:s,t,s|t,和 s|e|t。如对于边 prep_of(qfocus=name,brother),我们可以抽取这样四个特征:qfocus=what,brother,qfocus=what|brother 和 qfocus=what|prep_of|brother。
候选答案特征:对于主题图中的每一个节点,我们都可以抽取出以下特征:该节点的所有关系(relation,记作 rel),和该节点的所有属性(property,如 type/gender/age)。(注:我在揭开知识库问答KB-QA的面纱1·简介篇中对知识库中属性和关系的区别进行了讲解)
对于 Justin Bieber 这个 topic 我们可以在知识库找到它对应的主题图,如下图所示:
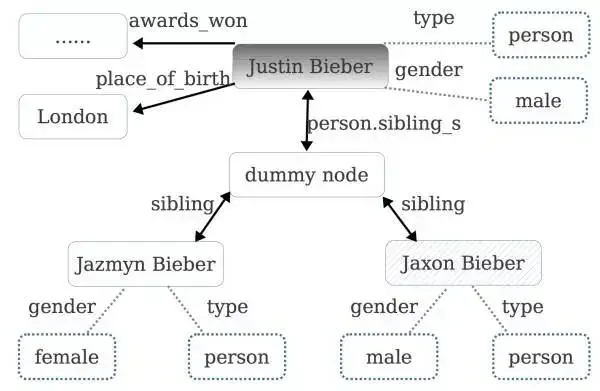
(注:图中虚线表示属性,实线表示关系,虚线框即属性值,实现框为 topic node。在知识库中,如果同一个 topic 节点的同一个关系对应了多个实体,如 Justin Bieber 的 preon.sibing_s 关系可能对应多个实体,那么 freebase 中会设置一个虚拟的dummy node,来连接所有相关的实体)
例如,对于 Jaxon Bieber 这个 topic 节点,我们可以提取出这些特征:gender=male,type=person,rel=sibling 。可以看出关系和属性都刻画了这个候选答案的特征,对判断它是否是正确答案有很大的帮助。
问题-候选答案特征:每一个问题-候选答案特征由问题特征中的一个特征和候选答案特征中的一个特征,组合(combine)而成(组合记作 | )。
我们希望一个关联度较高的问题-候选答案特征有较高的权重,比如对于问题-候选答案特征 qfocus=money|node type=currency(注意,这里 qfocus=money 是来自问题的特征,而 node type=currency 则是来自候选答案的特征),我们希望它的权重较高,而对于问题-候选答案特征 qfocus=money|node type=person 我们希望它的权重较低。
接下来我们用 WebQuestion 作为训练数据,使用 Stanford CoreNLP 帮助我们对问题进行信息抽取。训练集中约有 3000 个问题,每个问题对应的主题图约含 1000 个节点,共计有 3 million 的节点和 7 million 种问题-候选答案特征。
作者用带 L1 正则化的逻辑回归(logistic regression)作为分类器,训练每种问题-候选答案特征的权值(L1 正则化的逻辑回归很适合处理这种稀疏的特征向量,作者表示其效果好于感知机 Percptron 和支持向量机 SVM)。 训练完毕后,得到了 3 万个非零的特征,下表列出了部分特征和它相应的权值,可以看出问题特征和候选答案特征相关度较高时,其权值较高。

因此,在使用的时候,对于每一个候选答案,我们抽取出它的特征(假设有 k 个特征)后,再和问题中的每一个特征两两结合(假设有 m 个特征),那么我们就得到了 k*m 个问题-候选答案特征,因此我们的输入向量就是一个 k*m-hot(即 k*m 维为 1,其余维为 0)的 3 万维向量。
在提取候选答案的特征时,我们对每个实体提取了它的关系和属性,在论文中,作者还额外提取了一个更强力的特征,即每一个关系 R 和整个问题 Q 的关联度,可表示为概率的形式 P(R|Q)。那么这个概率如何求解呢?作者采用朴素贝叶斯,backoff model(即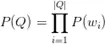 )的思想和假设,对于
)的思想和假设,对于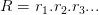 这种复合关系,people.person.parents,也采用 backoff 的思想(即
这种复合关系,people.person.parents,也采用 backoff 的思想(即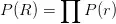 )这个概率进行近似,即:
)这个概率进行近似,即:
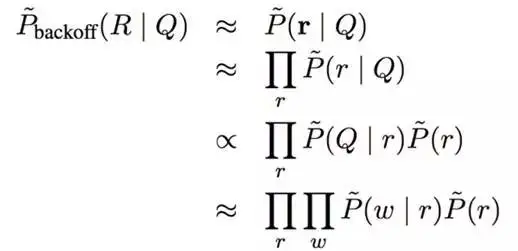
作者通过 freebase 知识库和两个数据集分别对上面的概率进行统计估算。第一个数据集是 Berant J, Chou A, Frostig R, et al. 中 Semantic Parsing on Freebase from Question-Answer Pairs 使用到的利用 ReVerbopen IE system 在 ClueWeb09 抽取的三元组数据集,包含了 15 million 个三元组,该数据集记作 ReverbMapping,第二个数据集是含 1.2 billion 对齐对(alignment pairs)的 CluewebMapping。
值得一提的是,这些数据中并不直接包含知识库中的关系 rel,那么要如何去估算 P(w|r) 呢?作者采用了一个近似的办法,如果一个数据集中的三元组包含的两个实体和知识库中的关系 r 包含的两个实体一样,就认为这个三元组中存在该关系 r,计数加一。
在两个数据集上分别完成统计和计算后,作者使用了 WebQuestion 进行了测试,分别计算给定每一个问题 Q,答案对应的 relation,它们的概率和其他 relation 相比,排名在 top1, top5, top10, top50, top100 和 100 之后这六种情况的百分比,如下表所示:
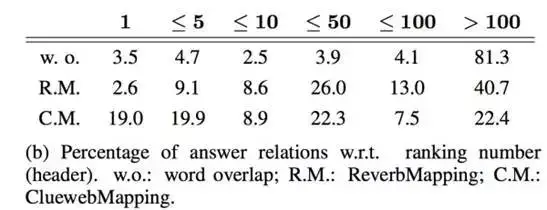
可以看出当使用 ClueWebMapping 这个超大数据集训练后,给定一个问题,每次选择概率最高的 rel 时,有 19% 的正确率。因此,作者对于主题图中的每一个候选答案,增加这样一种特征,即该候选答案对应的每一个关系 rel,其概率 P(rel|Q) 在所有关系中的排名情况(如 top1、top3、top5、top50、top100 等等),比如特征 income_relation_rank=top_3(这里因为 relation 是有方向的,所以用 income 前缀对方向加以区分)。
至此,我们已经搞清楚了这篇文章方法涉及到的所有元素:问题特征,候选答案特征,每个候选答案和问题的特征向量以及分类器。最后,我们再简单介绍下实验。
4. 论文实验与总结
候选答案的主题图是根据问题中的主题词确定的,而一个问题可能包含多个主题词。作者先通过命名实体识别提取问题中的所有命名实体(如果提取不到一个命名实体,则使用名词短语代替),将所有命名实体输入到 Freebase Search API 中,选取返回排名最高的作为最终的主题词,使用 Freebase Topic API 得到相应的主题图。
当然使用 Freebase Search API 这个方法可能会错过真正和答案相关的主题词(topic),作者也测试了模型在真实的主题词(Gold Retrieval)下的 F1 score,结果如下:

可以看出,信息抽取的这个方法,相比我在揭开知识库问答KB-QA的面纱2·语义解析篇中介绍的 Semantic Parsing on Freebase from Question-Answer Pairs 方法在 F1-score 下有较高的提升,到达了 42.0 的 F1-score。
信息抽取的办法,总体来说涉及到了不少 linguistic 的知识,比较符合人类的直觉。虽然也涉及到了很多手工和先验知识的东西,但个人认为它的思想还是很不错的。
作者在构造候选答案特征时,引入了和 P(R|Q) 相关的特征,这个思路是一个很好的思路,但是对 P(R|Q) 的估计方式总体来说还是比较粗暴(比如使用 backoff),个人认为可以使用 Deep Learning 的方法进行提升。
