



一只猴子在树林之间敏捷而灵活地跳跃穿梭,或者一名足球运动员快速带球过人、劲射得分,这些表现皆令人惊叹。掌握这种精密复杂的运动控制是物理智能(physical intelligence)成熟的标志,同时也是人工智能研究中的关键一环。
真正的运动智能需要学习控制和协调身体的灵活性从而完成复杂环境之中的任务。控制物理仿真类人身体的尝试来自多个领域,包括计算机动画和生物力学(biomechanics)。存在一种使用手工对象(有时带有动作捕捉数据)生成特定行为的趋势。然而,这可能需要相当多的工程学努力,且会产生受限的行为,或难以泛化到其他新任务的行为。
在这三篇论文中(论文摘要见后文),我们寻找了产生灵活和自然行为的新方法,它们可被再利用,解决新任务。
富环境中移动行为的出现
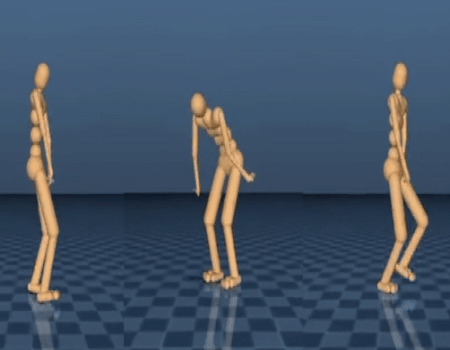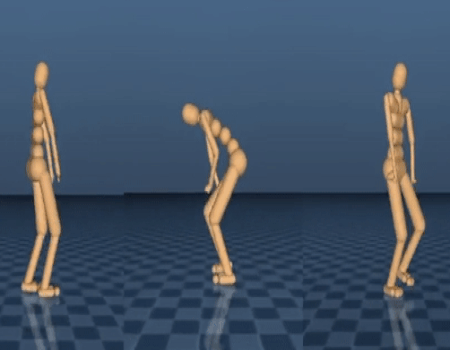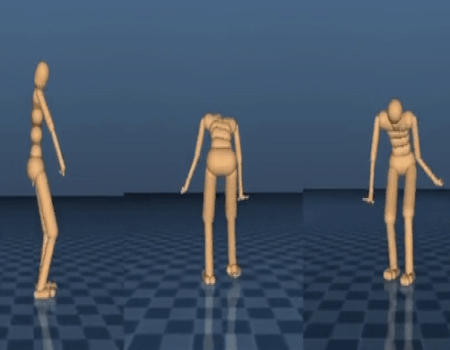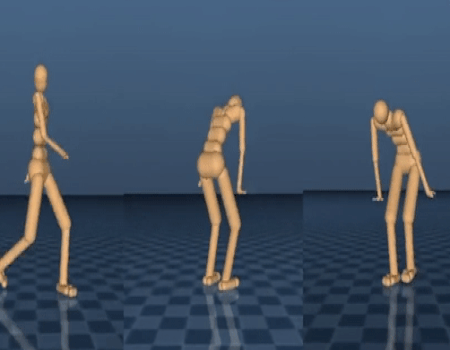
对于一些人工智能问题,比如玩Atari 或下围棋,其目标易于定义,即获胜。但是你如何描述定义一个后空翻动作,或者跳跃。当教授人工系统学习运动技能时,精确描述复杂行为的困难是普遍存在的。在这一工作中,仅通过使用高水平的对象(比如向前移动而不摔倒),我们探索了如何通过身体与环境的交互从头创建精密的行为。尤其地,我们使带有不同仿真身体的智能体穿过不同的地形(这需要跳跃、转向、蹲伏),从而完成其训练。结果表明智能体在没有特殊指示的情况下发展出了复杂技能,这一方法可被应用于训练系统中多个不同的仿真身体。下面的动图展示了该技术如何带来高质量动作和持久力。

一个仿真的 “平面 ”行走者('planar' walker)反复尝试翻过一堵墙。

一个仿真的 “蚂蚁 ”行走者学习在木板间进行准确跳跃的动作。
通过对抗式模仿从动态捕捉中学习人类行为
上文提到的突发行为极具鲁棒性,但是由于这些动作必须从头开始,它们往往与人类动作并不相似。在第二篇论文中,我们展示了如何训练一个策略网络(policy network),它可以模仿人类行为的动态捕捉数据,以对行走、起立、跑步、转弯等特定动作进行预学习。一旦输出的动作更接近人类,我们就可以调整并重新利用这些动作来解决其他任务,如爬楼梯、在密封走廊内行走等。
点击此处可查看全部动图(https://youtu.be/hx_bgoTF7bs)。
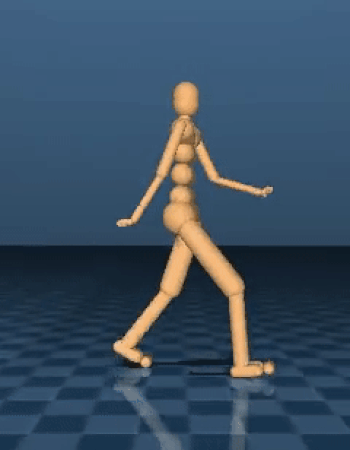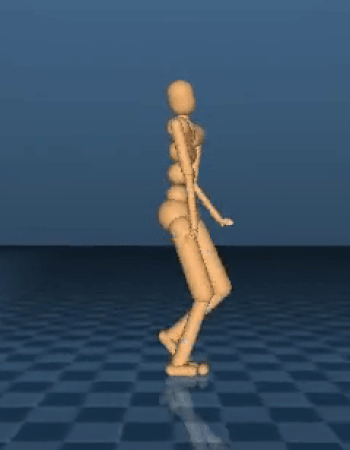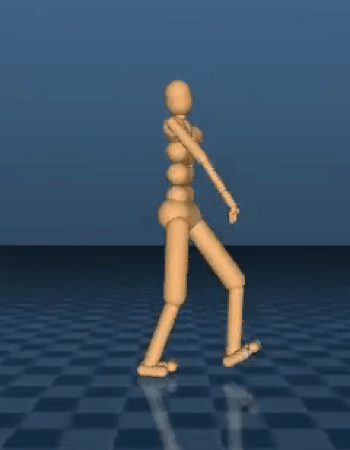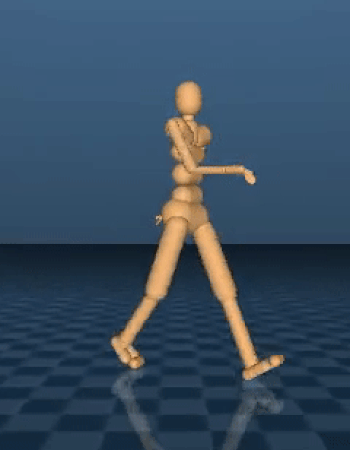
类人步行者生成与人类相似的行走行为。

仿真步行者摔倒以后成功地站了起来。
多行为的鲁棒性模仿
第三篇论文提出了一个神经网络结构,它基于最新的生成模型,这种结构能够学习不同行为之间的关系,并模仿一些特定动作。训练之后,我们的系统可以对一个被观察的单一动作进行编码,并且在其示范的基础上创建一个全新的动作。它也可以在不同种类的行为间进行切换,即便之前从来没有见过它们之间的转换,例如行走方式之间的转变。
左端和中间的这两个模型展示了两个示范行为。右边的智能体模型则根据这些行为生成了一个全新的转化(transition)。

左边的模型,平面行走者(planar walker)演示了一个特定的行走方式。右边的模型中,我们的智能体使用一种单一的策略网络(policy network)来模仿此种行走方式。
论文一:富环境中移动行为的出现(Emergence of Locomotion Behaviours in Rich Environments)

论文地址:
https://arxiv.org/abs/1707.02286
摘要:强化学习范式原则上允许从简单的奖励信号中直接学习复杂行为。然而实际上,小心地手动设计奖励函数以鼓励一个特定方案,或者从演示数据中获取是惯常情况。这篇论文探索了富环境如何帮助提升复杂行为的学习。尤其是,我们在不同的环境语境中训练智能体,并发现这鼓励了在一系列任务中表现良好的鲁棒行为的出现。我们为移动演示了这一原则——已知的行为是出于其对奖励选择的敏感性。通过使用基于前向进程的一个简单的奖励函数,我们在一系列不同的充满挑战的地形和障碍中训练若干个仿真身体。通过一个策略梯度强化学习的全新可扩展变体,我们的智能体学习奔跑、跳跃、蹲伏和转向,而无需来自环境的明确奖励指示。
这一学习性行为的亮点的可视化描述可参见 https://goo.gl/8rTx2F 。
论文二:通过对抗式模仿学习利用动态捕捉学习人类行为(Learning human behaviors from motion capture by adversarial imitation)

论文地址:
https://arxiv.org/abs/1707.02201摘要:深度强化学习领域的快速发展增加了为高维类人体训练控制器的可行性。然而,强化学习仅具备简单的奖励函数,使用这种方法生成的动作往往非常僵硬,且不像人类动作。我们将在本论文中论述如何使用生成对抗模仿学习(generative adversarial imitation learning)训练通用神经网络策略,从而根据有限的示例生成与人类相似的动作模式,这些示例仅包括部分观察到的状态特征,不包含具体动作,甚至它们的发出体具备不同、未知的物理参数。我们使用该方法,利用动态捕捉数据建立多个子技能策略网络(sub-skill policy),并证明这些策略网络可被再利用,用来解决来自更高级别控制器的任务。
论文三:多行为的鲁棒性模拟(Robust Imitation of Diverse Behaviors)

论文地址:https://deepmind.com/documents/95/diverse_arxiv.pdf
摘要:深度生成模型最近已经在运动控制的模仿性学习方面展现示出了很大的潜力。在给定足够数据的情况下,即使是监督方法也可以进行一次性模拟学习(one-shot imitation learning);然而,当智能体轨迹与示例偏离时,它们很容易受到连锁故障的困扰。与纯监督方法相比较,生成对抗模仿学习(GAIL)可以从更少的示例中进行更鲁棒的控制学习,但是从根本上来讲它需要进行模式搜索,并且难以训练。在本论文中,我们展示了如何将这两种方法的有利方面进行结合。我们的模型基础是一种新型的用于示例轨迹的变量自编码器,可以对语义策略嵌入进行学习。我们展示了这些嵌入式可以在 9 DoF Jaco 机械臂上被学习,然后顺利地内插进一个预期动作的结果平滑插值(resulting smooth interpolation)。利用策略表征,我们开发了一种新版本的 GAIL (1)比纯监督式调节器更具有鲁棒性,尤其是在示例较少的情况下,(2)避免了模式崩溃(mode collapse),当GAIL 依据其自身的时候就不再捕捉更多不同的行为 。我们展示了我们的方法可以从一个2D 二足模型和一个MuJoCo 物理环境中的62 DoF 3D 类人模型的相关示范中对不同的步态进行学习。



