




是时候停止把Facebook当作纯粹的社交媒体公司来看了。它用无人机提供互联网服务,为了发展虚拟现实而收购Oculus,不懈追求人工智能,Facebook已经迅速成为世界上最先进的技术研究中心之一了。 无独有偶,谷歌甚至IBM之类的公司也有类似的计划,总的来说,人工智能领域的发展已经提速到无疑会影响到人机交互的节点了。事实上,这已经发生了,不过是悄悄地在幕后进行。每月为15亿用户提供服务的Facebook对人工智能技术兴趣浓厚。Facebook解决的是模拟一般智力的问题——即让计算机日渐脱离线性逻辑的机器的思考方式,而是像我们自由形态的人类以多管齐下的方式来思考。Facebook人工智能研究室(FAIR)致力于解决广义的人工智能的问题,而语言技术项目组和Facebook M(虚拟助手)这类规模稍小的项目组则致力于开发用户操作中会用到的实际功能。
Facebook人工智能研究室的诞生
一切始于2013年,Facebook创始人兼CEO Mark Zuckerberg、CTO Mike Schroepfer和其他公司高层在评估公司上线十年以来的成就,并思考在接下来的十年、二十年如何长盛不衰。 Facebook已经将机器学习运用到其流行的社交网络中,比如说决定用户会在News Feeds中看到什么内容。不过相比起当时前沿的神经网络成果,这不过是小儿科。
一些Facebook工程师也一直在尝试积卷神经网络(CNNs),这是一种非常强大的机器学习,现在普遍被用于图像识别。 即便人工智能还处于发展初期,Zuckerberg对它的潜力非常看好,因此他从谷歌大脑(Google Brain)挖了一位叫做Marc』Aurelio Ranzato的工程师。然后他追本溯源找到了积卷神经网络的发明者——Yann LeCun。 Facebook人工智能实验室负责人Yann LeCun是人工智能界的一个传奇。他最早在1988年在贝尔实验室担任研究员(由电话之父Alexander Graham Bell创立,并因其在电信技术领域的无数领域的实验而闻名)开始他的研究,然后在AT&T实验室担任部门主管直到2003年。那之后他开始在纽约大学任教。现代的卷积神经网络是 LeCun职业生涯的巅峰之作。你是否曾经好奇过ATM怎么能识别你的支票?这就得益于 LeCun负责的「SN」的神经网路模拟器的早期研究,于1996年被采用。
「我希望你建立起全世界最好的人工智能研究实验室。」
「我开始和Schroepfer 和Mark接洽,我想他们也许喜欢我向他们讲述的东西」,LeCun在接受《Popular Science》采访中说道:「他们试图说服我来运作这个实验室……当像Mark 那样的人跑过来和你说:『好吧,你基本上接受了全权委托。你能组建世界一流的研究室,我希望你建立起全世界最好的人工智能研究实验室』。我的回答将会是:『嗯,相当有意思的挑战。』」 关于世界顶级的研究室是什么样子,Yann有自己的想法。如果你想要吸引顶尖人才,你得有一个雄心勃勃的研究室,有着雄心勃勃的长期目标。然后你还得给他们工作上的自由权,同时对你的研究你必须持有非常开放的态度。「这和Facebook的信念有几分吻合,Facebook秉持着开放的理念。」LeCun说。
组建团队
这个肩负着Facebook的未来的团队规模很小,由大约 30个研究科学家和15名工程师组成。团队有三个分支:Facebook人工智能研究组的主要办公室位于纽约市的Astor Place,由LeCun管理着一个由20名工程师和研究人员组成的团队。Menlo Park的是一个同等规模的分支。六月,FAIR又在巴黎设立了一个更小的5人组,与INRIA(法国计算机科学与自动化研究机构)合作。还有很多在Facebook其他部门一起合作致力于人工智能发展的团队,例如语言技术团队;FAIR只是主要的研究部门。 这些研究人员和工程师来自科技领域的各个层面,同时当中很多人都曾与Lecun合作过。高等级的人工智能研究并非是一个庞大的领域,而且Lecun的很多学生都创建了人工智能方面的初创公司,它们一般会被像Twitter这样更大的企业收购。
Lecun曾经告诉《连线》杂志,「深度学习实际上是Geofff Hinton,我,还有蒙特利尔大学的Yoshua Bengio之间的一个阴谋。」 Hinton在谷歌研发人工智能, Bengio奔波于蒙特利尔大学和数据挖掘公司Apstat之间,而LeCun也与其他行业内的著名企业有千丝万缕的关联。 「当我第一次在贝尔实验室做到部门主管时,我的老板对我说,「你需要记住两点:首先,永远不要让自己陷入团队内部的竞争。第二,只雇佣那些比你更聪明的人,」LeCun说。 负责领导语言研究子群的Leon Bottou,是LeCun的一个老同事。他们一同研发了神经网络模拟器,1987年的AmigaOS就是他们的第一个作品。Bottou 2015年3月加入的FAIR,此前他在为微软研究组工作的同时,还致力于机器学习和机器推理的探索。

从左数起,Leon Bottou, Yann LeCun, 还有Rob Fergus,在Facebook的纽约办公室里工作。[/caption]
2014年11月,LeCun请来 Vladimir Vapnik作为他们的团队顾问。Vapnik和LeCun曾一起在贝尔实验室工作,发表了关于机器学习的形成性研究,其中包括一项测量机器学习能力的技术。Vapnik是统计学习理论之父,统计学习理论即基于既定数据的预测。预测,对人类来说似乎是一个简单的任务,实际上却需要关于预先形成的概念和对世界的观察的海量信息(更多是后者)。Vapnik,这一领域的先驱,基于他在知识传播上的兴趣,继续着这一领域的工作,并把师生互动时的线索运用在机器学习当中。
目标
团队的规模和科研力量允许Facebook拥有雄心勃勃的长期目标,绝不会达不到被LeCun称为「明确的智慧」的标准。 「迄今,最好的人工智能系统也是愚钝的,因为它们没有常识。」LeCun说道。他用一种情况举例,比如我拿起一个瓶子,然后离开房间。(我们在纽约Facebook的会议室里讨论真正的机器智能的诞生,而这个房间的名字却不怎么吉利—— Gozer the Gozerian,与《捉鬼敢死队》里面的反派同名。)人类的大脑不难想象出一个人拿起瓶子然后离开房间这么个简单的场景,但对一台机器来说,仅这个前提就会导致大量的信息缺失。 Yann一边说,我一边在心中想象这个场景:」你很可能站起来,即使我在语句中没有提到,你也很可能走动;你打开门,走进去,也许还会关上门;瓶子不在房间里。由于知道真实世界的情况和界限,你可以借由判断。因此我并不需要告诉你所有的细节。」 现在对于机器如何学习该水平的推理,人工智能领域的专家知道得并不多。在向这个目标迈进途中,Facebook正致力于制造能足够好地学习已知世界的机器。
「迄今,最好的人工智能系统也是愚钝的。」
LeCun说:」最大的障碍是自助式学习(unsupervised learning)。」现在机器主要通过一两种方式进行学习,即他助式学习(supervised learning)——在系统中,向机器展示成千上万的狗的图片,直到机器了解了狗的特征。谷歌的DeepDream以研究者反转流程以揭示出其有效性对这一方法进行了阐释。 另一种方式是增强学习(reinforcement learning),即机器对给出的信息以是或否的二择一的方式进行选择,以给出一个答案。这种学习耗费的时间稍长,但是机器被强制由自身做出内在的抉择。当这两种学习方式结合起来时,就会产生强大结果。(还记得DeepMind Atari吗)。自助式学习不需要反馈或者输入,LeCun表示这就是人类的学习方式。我们发现、得出结论,并将其加入到人类的知识库存之中。这,被证明是一项艰巨的任务。 LeCun笑着说:」我们甚至没有一个用以发展人工智能的基本指导原则,很明显,我们在努力寻找。我们有很多点子,只是目前没一个奏效罢了。」
真正人工智能的早期探索
但是这并不是说以前的探索没有成果。现在让LeCun激动的是关于」记忆网络」的工作,其可以被整合进积卷神经网络,并使它们获得记忆保持的能力。LeCun把这个新的记忆模型比作大脑中的分别由海马体和大脑皮层控制的短期记忆和长期记忆(LeCun厌恶把CNNs比作大脑,相反他更喜欢这个模型:一个带有50亿把手的黑箱)。 记忆单元允许研究者向该」记忆网络」讲说一个故事,随后使该网络回答关于这个故事的问题。 故事选自《指环王》一书。我们不把全书而是书中主要情节的简短概述(」比尔博拿到了魔戒」)讲给」记忆网络」,当被问及在书中某一具体情节中魔戒在哪里,这个」记忆网络」能做出简短正确的回答。Facebook 熟悉科学官Mike Schroepfer说(他强调技术可以帮助Facebook以更高的精确度向人们展示其想看到的)这意味着它理解书中事物与时间的关系。
「通过搭建能理解世界的本质、了解你所想要的是什么的系统,我们就能帮助你。」 Schroepfer在三月的一个开发者报告会上说道:「我们能搭建出一个系统,确保让所有人可以把时间花在他们真正关心的事情上。」 FAIR团队正在围绕这个目标开发一个被称为「嵌入世界」的项目。在该项目中,为了帮助机器更好的理解现实,FAIR团队正在教它们用向量表示所有事物之间的关系,如:图像,帖子,评论,相片及视频等之间的关系。神经网络也在构建一个包含了能组合媒体内容、不同个体之间的距离等错综复杂内容的体系。
嵌入世界
Lecun说通过使用这一系统能让我们开始「用代数替换原因」。这表示着让人难以置信的强大。在嵌入世界项目中开发的人工神经网络能够根据视觉相似性将在同一地点拍摄的两张不同照片连接起来,并能指出文字描述是否符合场景。它重建了现实的一种虚拟记忆,并将之在其他地方和事件的背景下进行聚类。它甚至能根据一个人之前的喜好,兴趣以及数字经历「虚拟地表示这个人」。虽然这还只是带有实验性质的,但是对Facebook 的新闻流呈现具有很大的影响,在跟踪标签上也进行了一定的使用。
「如果我们有一个切实有效的想法,我们就能让它在一个月内被15亿人使用。」
有很多关于长期目标的演说,但恰恰是小的胜利让Facebook不断前行。在2014年6月,他们发表了一篇名为「DeepFace:缩小人类表现与人脸识别间差距」的文章,该文宣称在Facebook的这项技术在人脸识别中已达到97%的准确率。Lecun说:他相信Facebook的人脸识别技术已达到世界第一,这也是Facebook与学术研究机构的一个关键性的区别。现在,DeepFace是Facebook自动标记照片背后的驱动力。 「如果我们有一个切实有效的想法,我们就能让它在一个月内出现在15亿人面前。」LeCun说,「让我们把目光聚焦在我们的长期目标的高度上,但是,在这个过程中会有很多我们将要去实现的会在短期具有实用性质的事。」
作为FAIR的研究成员之一的Rob Fergus,正在纽约办公室处理有关人工智能虚拟方面的工作
作为在NYU和MIT计算机科学和人工智能实验室工作过的老手,Rob Fergus领导着有关计算机视觉的AI团队。他们的工作已经在自动标记相片上得到使用,接下来将被用于标记视频。大量视频因为缺乏元数据,或者没有任何描述性文本,而被「淹没」于噪声中。AI将会能够「观看」视频,并将它们大致分类。
这对Facebook阻止那些不想被上传到他们服务器上的内容具有巨大的意义---例如色情照片,版权问题或者其他违反他们使用条款的任何内容。它也能鉴别新闻事件,对不同类型的视频进行管理。Facebook此前一直将这些任务划分给外包公司,当这项技术稳定后,Facebook就能降低这部分的人工成本。 在目前的测试中,人工智能表现得很有希望。给它播放一段正在进行的体育视频,比如冰球、篮球或乒乓球,人工智能能够准确地识别出这个体育项目。并且还可以区分垒球和棒球,漂流和皮划艇,以及篮球和街球这些类似的运动。

Facebook背后的人工智能
Facebook有一个叫做语言科技的独立小组,主要负责开发翻译,语言辨识和自然语言理解。LeCun所在的部门,Facebook人工智能研究室(FAIR)是Facebook人工智能战略研究的主力,而语言科技(从属于应用机器学习)是实际进行软件开发的地方。
他们与FAIR合作,但独立进行开发和实践,并且已经开发了493种广泛使用的翻译方向(从英语到法语,从法语到英语算两种方向)。 本着让世界更开放更连通的宗旨,语言服务是Facebook的一条必经之路。超过一半以上的Facebook用户不说英语,然而Facebook上大部分的内容都是通过英语呈现的,语言科技小组的负责人Alan Packer说道。 约有三亿三千万用户经常点击「见翻译」按钮使用这些翻译服务。如下图所示:

如果你是第一个点击翻译按钮的人,恭喜,你已经操作了人工智能了。首次点击会向服务器发出翻译请求,之后该请求将存储起来供其他用户使用。Packer说,夏奇拉(Shakira,著名拉丁裔歌手)发布的内容总是很快就翻译出来了。语言科技小组还推出了本地内容翻译,通过点击「见原文」按钮可以体验这项服务。 如果你是第一个点击翻译按钮的人,恭喜,你已经开始操作人工智能了。
人工智能是这项任务里一个必要的环节,因为「傻瓜」翻译对于人们彼此之间相互沟通作用不大,还会生成不正确的语法,误读的习语,俚语也无从参考。这就是过去Google翻译那种直接逐词翻译的缺陷。 Packer说,修辞尤其难翻译,但人工智能可以把握一些语义层面的含义。 「如果把『热狗(hot dog)』这个词组按字面翻译成法语,是说不通的。『Chaud chien』对法国人来说没有任何意义,」Packer说道。「同样如果你拿着一幅我滑雪的照片,我说,『我今天秀了一下滑雪技巧(I'm hot dogging it today),』这就变得很难理解,因为这里的hot dogging是炫耀的意思。」 尽管这种理解并不算太多,但早期的结果预示着这个任务很难处理。Packer说,人工智能的妙处在于它不会去理解比喻或习语,但仍会在不理解的同时认识到这一点。
人工智能本身具有适应性,经过训练后便可以很快掌握俚语。语言科技小组最近发现法国球迷在用一个新俚语表达「wow」,人工智能在接受那部分公用数据的神经网络训练以后,现在能够可靠地将文本翻译出来。他们通过每天对人工智能进行新数据的训练扩展Facebook的词库,不过所有语言的词库正在按月更新。
Facebook M
我们已经习惯于个人数字助理,比如Siri,Cortana,以及Google Now。但Facebook选择了一条不同的道路,其名为「M」的新型个人AI助理拥有超越手机界限处理复杂事物的能力。Siri可以发短信,而M可以预定航班或制定旅行计划。在开发过程中,一位Facebook的雇员甚至让M安排了一个找搬家公司到家中进行评估的日程。(不过当然了,你不能让M给你买烟草、酒、枪支,或者给你安排色情服务。)
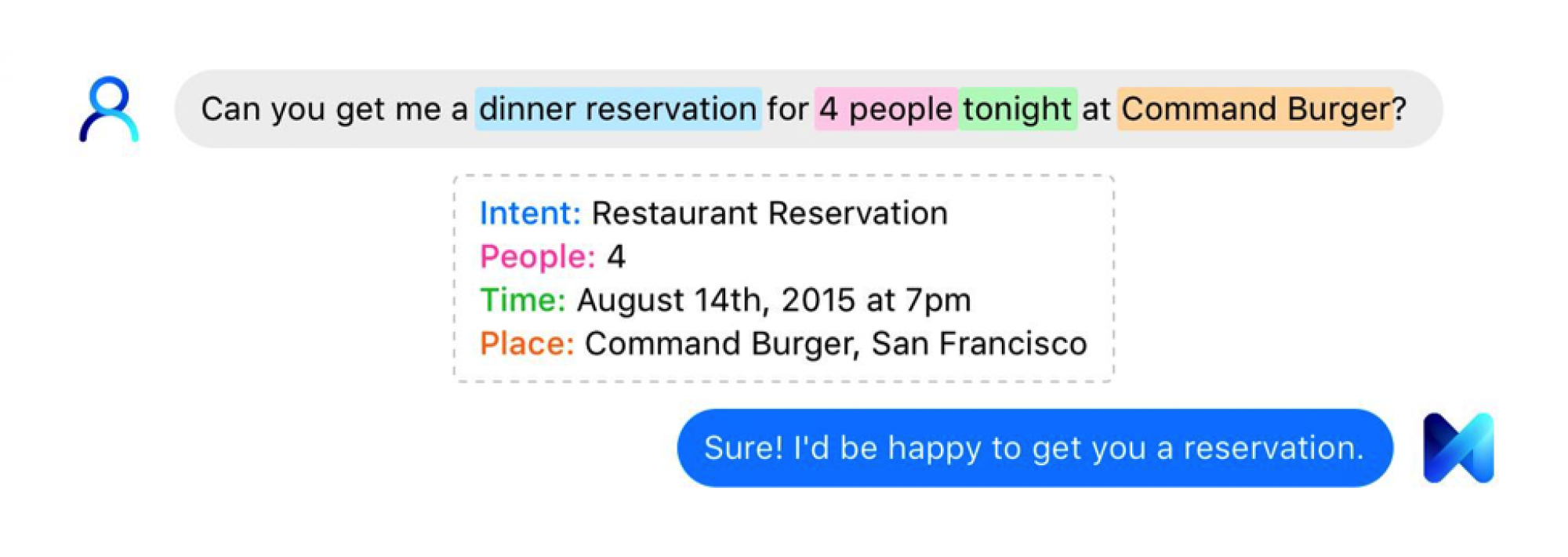
在三年内,M有可能能够给有线电视公司或者车辆管理部门打电话,并帮用户在线等待,直到对方的接线员接过电话。 事实上,Facebook M的主干来自于今年早些时候收购的一家创业公司:Wit.ia。他们加入了Messenger的小组,受VP David Marcus的管理,并在本月早些时候首次发布了M。
Alex LeBrun在Facebook内部领导Wit.ai小组,他说人工智能不仅帮助M更好地完成一般的任务,也能完成有一些特殊情况的任务,如带一个小婴儿旅游,或在灯火管制日的时候旅行。这也意味着M的能力随着人工智能的发展而发展。他乐观地认为,在三年内,M就可能有能力呼叫有线电视公司或者车辆管理部门,并帮助用户在线等待,直到有人接过电话。
「M这样的服务最大的附加值在于它能够完全满足你的需求,甚至在你的需求比较特殊或比较奇怪的情况下,」 LeBrun 说,「在任务比较复杂或并非常理情况的时候,它也能完成任务。」 随着M的运行,它能够不断学习。现在,它还没有能力独自运行。一个被称为「AI训练者」的小组跟M一起工作,如果出现M不懂的任务,小组会接管过来。随后M可以从人类训练者身上学到应该怎么做,并应用到之后的任务中。在程序中还内嵌了一种随机机制,Lebrun说是为了让它更像人类学习的过程。
「AI训练者」是个新的职位,Facebook本身也在对这个职位的探索中。他们说,这并不是一个给研究员或者工程师的职位,而是为那些拥有客户服务经验的人准备的。Facebook将能够评估哪些任务需要人类的干预,但最后,他们希望在未来完成这些任务将不需要任何人类干预。
但在开发过程中,这个职位是必须的,因为他们的工作主要有两部分:一是保证服务质量的最后一道关卡,二是训练AI。
有人类智能做看门人,M可以在FAIR进行开发时当做沙盒来用。「如果有什么东西需要测试,就会在M中显现,因为在我们的训练和督导下,这个过程是没有风险的。」Lebrun说。
M平台是完全建立在Wit.ai的平台之上的(主要在Facebook收购前就已研发),但FAIR也会对用户和个人AI助理的交互过程产生的数据用作深度学习。
Facebook在人工智能团体中的角色
「我们的研究项目都是完全公开的。几乎我们做的每件事都会发布,大部分的代码也都是开源的」 LeCun 说道。你可以在 Facebook 的研究网站上和 ArXiv——一个收纳电脑科学、数学及物理研究的图书馆,找到这些出版物。 大多人工智能团体都是这样不隐秘的。 LeCun 已成为发展 Torch(一个针对AI 发展的C++算法库)的领军人物。LeCun带领他的团队,还有 Twitter 和 Google的 DeepMind 的研究人员合作,共同发展 Torch。许多现今在这个领域的专家都曾是LeCun的学生。 任何他们可能出版的资料,从与医学成像相关的资料到无人驾驶车,也都是公开以促进未来发展的,LeCun说道。Facebook的研究固然对他们的用户很重要,但它的核心价值更佳体现在让人类对如何更好地用机器来模仿智能的知识。
「这是当代最大最复杂的科学挑战之一」。
这是为什么Facebook是人工智能社区中重要的一部分,也是为什么这个社区本身是如此重要。 「那些你在好莱坞电影里看到的情节,譬如一个在阿拉斯加与世隔绝的人研究出了完美运作,并在当下无人企及的人工智能系统,是完全不可能的」。LeCun说,「这是当代最大最复杂的科学挑战之一,没有任何一个人,甚至一个大公司能够凭他们自己解决。解决它需要整个研究发展社区的集体力量」。
