




编者按:本文是机器之心对科大讯飞副总裁、研究院院长胡郁的专访整理。本次专访中,胡郁对语音识别技术的历史、目前语音识别技术应用中的问题和解决方案、人工智能的未来发展方向发表了精彩论述。在此前的专访中,胡郁也曾对AI和科大讯飞战略的做过阐述。
语音识别技术的历史
1)语音识别技术的起源和隐马尔可夫模型
自出现电子计算机后,最早的语音识别系统起源于贝尔实验室(编者注:贝尔实验室开发的Audrey,它能够识别10个英文数字,这是最早的机遇电子计算机的语音识别系统),之后从50年代到90年代,语音识别领域又出现了几个分支,包括IBM、卡耐基梅隆大学和剑桥大学,这几个机构和贝尔实验室拥有在语音识别领域的绝对统治权。 语音识别领域被隐马尔可夫模型(编者注:Hidden Markov Model,简称HMM。隐马尔可夫模型是用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。该模型最初是在20世纪60年代后半期Leonard E. Baum和其它一些作者在一系列的统计学论文中描述的,最初的应用之一是开始于20世纪70年代中期的语音识别。)统治了很长时间。
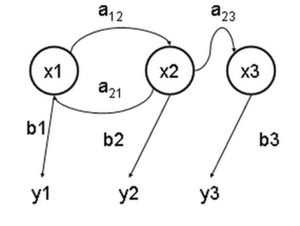
隐马尔可夫模型,图片来自维基百科
于语音识别,前三十年一直有人在做理论论证的东西,毕业于卡耐基梅隆大学的James K. Baker起先在IBM Continuous Speech Recognition Group做研究,后来创办了Dragon Systems,他是世界上第一个把隐马尔可夫模型用于语音识别的人,而且还做到了可以用。后来他的公司不是很成功,但他是在语音识别发展史上享有声誉的人。 当时,MIT也有人做语音识别;贝尔实验室开发了语音识别的决策理论和训练算法等。贝尔实验室解散之后,剑桥大学接过语音识别的大旗成为核心,但都不好用,原因是没有大数据和涟漪效应。
2)大数据、涟漪效应和深度神经网络带来的语音识别爆发
任何技术都有蓄能阶段和爆发阶段,语音识别技术的爆发就是源于大数据、伴随互联网出现的涟漪效应和深度神经网络。涟漪效应,指互联网思维在提高核心技术表现中的作用。也有人称之为优化迭代,比如百度吴恩达将其称之为把研究层、产品和用户使用组合在一起形成一个闭环的迭代优化,这是互联网思维在核心技术优化和突破所发挥作用的一种表达。通过这种方式不仅可以获取数据,还能学习经验、认识以及怎么使用等,比如说调整哪些东西让用户体验更好。
语音识别是需要经验、数据和用户反馈共同作用来提升表现的,需要利用用户的反馈总结出一些特点,比如说用户在说话时会截断,这样你就可以通过调整一些参数来提升表现。因为语音识别不仅仅是数据多了,识别率提高了,还有更多的因素,比如说用户的感觉、一些关键的参数点、经验等,这些都是可以学习到的。互联网思维所带来的就像软件迭代一样,通过反馈回来的信息进行调整,这是最核心的。 现在之所以有很多关于语音识别的观点是错误的,是因为他们没有意识到,不管是隐马尔可夫模型,还是深度神经网络,只是我们统计机器学习中不同的工具,有的工具好,有的工具差,有些新出的工具会优于之前的工具。至于用哪种统计模型和机器学习方法,这确实很重要,而且深度神经网络确实比别的好,但并不代表只有深度神经网络才能完成这样的事情,隐马尔可夫模型也可以,比如用在医疗行业的Nuance,科大讯飞在没用深度神经网络之前很早就意识到了这一点。隐马尔可夫模型有个局限,当数据量提升时,它带来的表现提升没有深度神经网络那么大,但其实都属于统计模式识别。
在语音识别发展的过程中,深度学习是同时发生的一件事,如果没有深度神经网络,但是有大数据和涟漪效应,隐马尔可夫模型也是可以做到实用。深度神经网络是让这个做的最好,降低了门槛,让更多人可以加入进来。在同样具有涟漪效应的情况下,深度神经网络比之前的算法好,数据越多,深度神经网络的效果更好。
3)语音识别中真正重要的环节是统计决策系统
还有更加重要的一点,深度神经网络只是整个统计机器模式识别理论框架中的一个环节而已,真正重要的环节是统计决策系统。语音识别是个decoding的搜索系统,深度神经网络是解决搜索系统中声学模型和语言模型得分的工具。统计决策系统的理论价值和意义比深度神经网络要大,但其太专业,深究的人并不多,准确的说应该是贝叶斯统计决策理论,深度神经网络只是用在统计决策理论中得分的一个工具,得分很重要。但这个统计决策理论是一套数学理论,有人证明了语音识别可以适用于这套设计,让decoding这个方法得到最优结果,从而证明了语音可以利用贝叶斯决策模型得到最优解,这是统计决策模型中最重要的一点。但目前很少有人知道这一点,因为它没有深度神经网络那么有名,但在专业人士看来,这个才是核心。语音识别怎么做能符合贝叶斯决策,在理论上能估计出上下限和收敛条件,大部分人对此不关心,可能很多做语音识别工作的人都不知道这一点,只知道套用深度神经网络得出结果,但不知道为什么。 因此,在整个统计决策模型中,贝叶斯决策起到关键作用,而有些模块让这个作用更大化,深度神经网络就是起到这个作用。先是有人发明了隐马尔可夫模型,繁荣了30年,伴随着隐马尔可夫模型成熟的是决策理论,当决策理论很成熟时出现了互联网带来的涟漪效应,使这些东西可以应用,这时又出现了深度神经网络,在这个大时代背景下使得决策理论的威力发挥到最大。只有知道以上这些关键技术和时间节点,才能弄清楚语音识别完整的发展历史,而语音识别链条上所有人的贡献才能得到公正认识。
4)科大讯飞语音识别的历史
科大讯飞很好的跟随了语音识别的发展历史,深度神经网络由Geoffrey Hinton与微软的邓力研究员最先开始做,科大讯飞迅速跟进,成为国内第一个在商用系统里使用深度神经网络的公司。谷歌是最早在全球范围内大规模使用深度神经网络的公司,谷歌的Voice Search也在最早开创了用互联网思维做语音识别。在这方面,科大讯飞受到了谷歌的启发,在国内最早把涟漪效应用在了语音识别上面,因此超越了其他平台。 科大讯飞最初使用隐马尔可夫模型,后面开始在互联网上做,2009年准备发布一个网页demo,同年9月份安卓发布之后开始转型移动互联网,并于2010年5月发布了一个可以使用的手机上的demo;2010年10月份发布了语音输入法和语音云。

科大讯飞副总裁、研究院院长胡郁
整个过程中最难的地方在于,当你不知道这件事情是否可行时,你能够证明它可行。美国那些公司就是在做这样的事情。而科大讯飞最先领悟到,并最先在国内做的。
对目前语音识别产品的思考
语音交互并不是在所有场景下都是刚需,比如说把手机放在一个地方同时在干其他事情,这就是刚需;并不是对所有人来说都是刚需,对年轻人来说就不见得是,因为他们能很方便的操作手机,但是很对于年纪大的人语音操纵可能就是。但语音对年轻人最有用的是输入,包括输入法、搜索、地图和记录。此外,在特定情景下一定是刚需,比如说可穿戴计算、远距操作的智能硬件、车载设备和黑色家电。在这些情况下,单靠语音识别、语义理解和语音合成是不能解决问题的,在这些场景下都都看不到手机屏幕,都需要远距操作,所以需要加上声学技术。 讯飞在过去有着多年积累并且取得卓越成就的就是在声学部分,解决了远距收集信息的问题。除了远距,还有自然交互,例如多轮和纠错。首先,大部分场景都需要远距,而解决这类场景下的问题不是靠一个技术,而是需要一系列技术,包括定位、麦克风波束形成、回声消除、抗混响、唤醒等等,这是一个系统,它可能比语音识别本身还要复杂。其次是对话控制,现在手机端的语音助手是单功的,按一下说一下,这需要变成全双工(注:通信专业词汇,指的是人和机器可以像打电话那样同时听和说)的实时通话。第三是多轮,是基于规则的对话控制中的一个环节。再加上纠错。还有一个支持多轮的是要了解用户,知道用户的背景。所有的这些东西加起来才是一个完整的语音识别系统。可以称之为核心技术系统创新。通过一系列系统创新的总和最终达到一个目的,这是才是上面提到的这些场景需求的解决方案。 Siri的出现所带来的语音识别助趋势不可阻挡,但我们需要看到这种趋势到来之后,认清哪一种核心技术系统创新和产品微创新能够解决用户的切实需求。在语音识别方面,科大讯飞传递的不仅仅是产品、技术,而是价值观,而这就是表现在严谨、态度和精确上,这和互联网领域的刚需是密切相关的,不是脱离需求去谈技术,而是基于具体应用,所有技术是为了解决刚需。 未来的语音交互在于不能只考虑语音识别技术,全双工的东西需要系统创新,要脱出语音识别的框架去做语音交互。要解决这些问题,如果分属不同组织架构、分属不同人管理,是做不出系统创新的,必须在统一管理下才能做出这样的系统创新。
总之,语音交互的核心包括语音识别本身等一系列技术,再加上语义理解,包括完成任务,聊天(目前达不到)、问答(查询信息,类似于Watson所作的事情)三个方面。而和语音交互相关的就是设备、刚需场景和环境。
科大讯飞的目标是借助技术创新实现人工智能
科大讯飞目前的重点已经不在局限于语音,我们提出的感知智能和认知智能已经远远超出了语音的范畴。科大讯飞目前所做的工作很多都是综合的,不会把语音单独拿出来,讯飞的最重目标是要实现人工智能。 我们都想要人工智能,但我们希望的人工智能是不带有自我意识的,自我意识和智能是可以分离的。之前人类想飞,会去模仿鸟类使用翅膀,但结果都失败了。但后来人类发现了飞行的根本因素——空气动力学,还发明了风洞。因此,我们人类现在不仅可以飞,还比鸟飞的好,也规避了鸟作为生物所带来的诸多不方便的东西。 我们要的人工智能就是一个能够像我们一样感知、认知、思考和决策的东西,但是不希望它有自我意识,就像一个机器一样。所有的科幻作品都有个假设,当机器达到这种智能时,必须会有自我意识,所以,所有的科幻作品都离不开阿西莫夫三定律。出现这种情况的原因是黑天鹅效应,如果有个东西的智能达到了人类水平,同时又没有自我意识,这种东西在世界上从来没有被我们发现过,所以我们认为这种东西不存在。但实际上这种东西是否存在呢?我们并不知道,只是我们每见过而已,所以我们要问两个问题,一个是是否有可能存在这样的东西,如果存在这样的东西,我们就没有必要讨论人工智能的善与恶,人类面临的风险,等等,因为它在没有自我意识的情况下就不会对人类产生危险。它会完全按照人类的命令行事。
第二是怎么达到?这里就是涉及神经科学的东西。神经科学有两个思路,一是大脑仿真,这条路在达到人类智能的情况下也势必会出现意识。还有一条路就是类似于「空气动力学」,也许我们可以在大脑中发现一个叫「智能动力学」的东西,通过分析人脑的神经网络找到智能部分,把这部分,包括认知智能和感知智能分离出来而不需要自我意识。但这里也会涉及一个偏哲学的考虑:也许这样的东西压根不存在;也许你在得到智能时就必须附带自我意识。
目前,大家都忽略了两个可能性,第一个是如果智能的自我意识分离不了,那人工智能有可能是善的,也有恶的。第二个可能性是智能和意识可以分离,我现在参与的很多脑科学的研究就是在往这个方向走,而且我认为这是有可能的。这个成功之后才真正是强人工智能,我们现在所做的事情都是弱人工智能,我们现在所使用的神经网络、涟漪效应和大数据做的再好也是弱人工智能。但只有用上面那种方法做出来的就有可能是强人工智能,而且是不带自我意识的强人工智能,这才是我们真正想要的东西,问题是需要有人先提出这个思路,提出这个东西可以做,有哪些路线,我们应该怎么去尝试才能做得到。 在强人工智能没有实现之前也可以先用弱人工智能来弥补一下,或者说,我们宁可要弱人工智能,也不要一个带有自我意识的强人工智能。现在有我们对这方面的思考还不够深刻,这个需要多学科交叉,只有深入研究神经科学,并且将其与信息科技结合,才能找到这条路。这个不是一种发明,而是一种探索发现,是科学家要做的事情。我们相信这种思路,而证明它唯一办法就是去实现它。
从现在来看,弱人工智能和强人工智能没有任何关系,而在弱人工智能中,统计机器学习方法只是弱人工智能实现的一个要素,即使在统计机器学习方法中,深度神经网络的重要性也要次于贝叶斯统计决策理论。 我们每天都可能会有新的观点,如果我们能够不断产生新的想法,我们就不会介意把这些想法分享出去的。同时对于人工智能的很多认识,更多的争论甚至理解可能都不是最重要的,关键是要把这些东西做出来,这需要强大的能力、资源、追求和团队去做这个事情,科大讯飞就是要做这样的事情,这是科大讯飞的追求,也是科大讯飞技术创新的宿命!



